
タンパク質は自然界で仕事をする分子であり、さまざまな用途のためにタンパク質をうまく改変して製造する業界全体が出現しています. しかし、そうするのは時間がかかり、でたらめです。 クレードル は、新しい構造と配列がどのような新しい構造と配列がタンパク質に彼らが望むことをさせるかを科学者に伝える AI を活用したツールで、それを変えることを目指しています。 同社は今日、かなりのシードラウンドでステルス状態から抜け出しました。
AI とタンパク質は最近ニュースになっていますが、主に DeepMind や Baker Lab などの研究機関の努力によるものです。 彼らの機械学習モデルは、簡単に収集できる RNA 配列データを取り込み、タンパク質がとる構造を予測します。これは、以前は数週間と高価な特別な装置を必要としたステップでした。
しかし、その機能が一部の分野で驚異的であるように、それは他の分野の出発点にすぎません。 タンパク質をより安定にする、または特定の他の分子に結合するように変更するには、その一般的な形状とサイズを理解するだけでは不十分です。
「あなたがタンパク質エンジニアで、特定の特性や機能をタンパク質に設計したい場合、それがどのように見えるかを知っているだけでは役に立ちません. 橋の写真を持っていても、それが落ちるかどうかわからないようなものです」と Cradle の CEO で共同設立者の Stef van Grieken 氏は説明します。
「Alphafold は配列を取得し、タンパク質がどのように見えるかを予測します」と彼は続けました。 「私たちはその生成的な兄弟です。設計したい特性を選択すると、モデルは実験室でテストできるシーケンスを生成します。」
どのようなタンパク質、特に科学的に新しいタンパク質が何をするかを予測する その場で さまざまな理由から困難な作業ですが、機械学習のコンテキストで最大の問題は、利用可能なデータが十分にないことです。 そのため、Cradle は独自のデータセットの多くをウェット ラボで作成し、タンパク質を次から次へとテストし、それらの配列のどのような変化がどのような影響をもたらすかを調べました。
興味深いことに、モデル自体は正確にはバイオテクノロジー固有のものではなく、GPT-3 のようなテキスト生成エンジンを作成した同じ「大規模言語モデル」から派生したものです。 Van Grieken 氏は、これらのモデルは、データを理解し予測する方法が言語に厳密に限定されていないことを指摘しました。これは、研究者がまだ調査している興味深い「一般化」の特徴です。
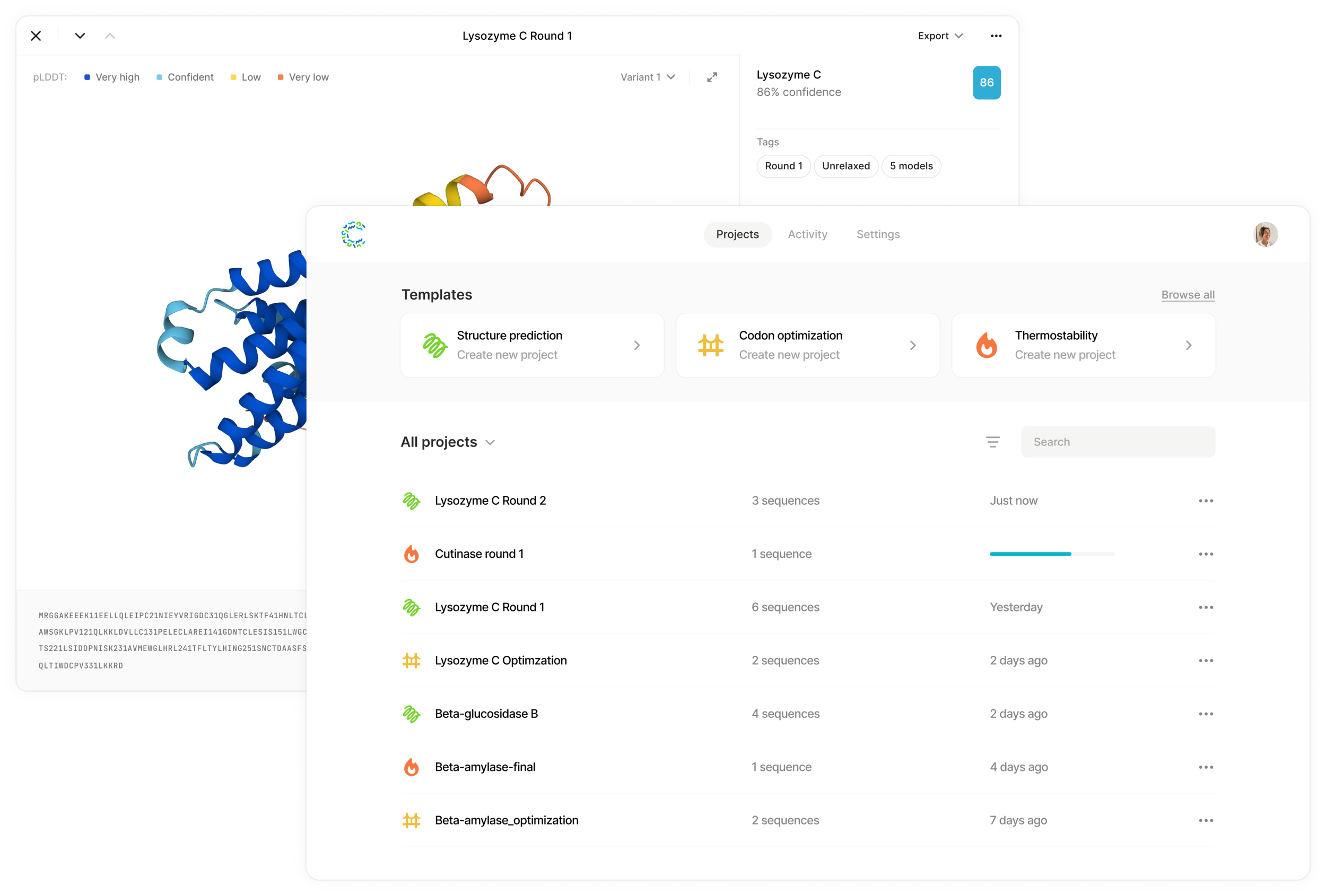
Cradle UI の動作例。 画像クレジット: クレードル
もちろん、Cradle が取り込んで予測するタンパク質配列は、私たちが知っている言語ではありませんが、関連する意味を持つテキストの比較的単純な線形配列です。 「エイリアンのプログラミング言語のようなものです」と van Grieken 氏は言います。
もちろん、タンパク質エンジニアは無力ではありませんが、彼らの仕事には必然的に多くの推測が含まれます. 彼らが変更している 100 のシーケンスの中に、望ましい効果を生み出す組み合わせがあることはかなり確実かもしれませんが、それ以上は徹底的なテストに帰着します。 ここでのちょっとしたヒントは、物事を大幅にスピードアップし、膨大な量の無駄な作業を避けることができます.
このモデルは 3 つの基本的なレイヤーで機能する、と彼は説明しました。 最初に、与えられたシーケンスが「自然」であるかどうかを評価します。 それがアミノ酸の意味のある配列であろうと、単なるランダムなものであろうと。 これは、文が英語 (または van Grieken の例ではスウェーデン語) であり、単語が正しい順序になっていることを 99% の信頼度で言うことができる言語モデルに似ています。 これは、ラボ分析によって決定された数百万のそのようなシーケンスを「読み取る」ことからわかっています。
次に、タンパク質のエイリアン言語の実際の意味または潜在的な意味を調べます。 「シーケンスを与えたと想像してください。これは、このシーケンスが崩壊する温度です」と彼は言いました。 「多くのシーケンスでこれを行うと、『これは自然に見える』だけでなく、『これは摂氏 26 度に見える』と言うことができます。 これは、モデルがタンパク質のどの領域に注目すべきかを判断するのに役立ちます。」
その後、モデルは挿入するシーケンスを提案できます — 基本的には知識に基づいた推測ですが、スクラッチよりも強力な出発点です。 エンジニアまたはラボはそれらを試して、そのデータを Cradle プラットフォームに戻し、そこで再取り込みして、状況に合わせてモデルを微調整するために使用できます。

晴れた日に本社で過ごす Cradle チーム (van Grieken が中央)。 画像クレジット: クレードル
さまざまな目的のためにタンパク質を修飾することは、医薬品の設計からバイオ製造まで、バイオテクノロジー全体で有用であり、バニラ分子からカスタマイズされた効果的かつ効率的な分子への道のりは長く、費用がかかる可能性があります. 少なくとも、1 つの良い結果を得るために何百回もの実験を実行しなければならないラボの技術者は、それを短縮する方法を歓迎するでしょう。
Cradle は秘密裏に活動しており、現在、Index Ventures と Kindred Capital が共同で主導するシード ラウンドで 550 万ドルを調達し、エンジェルの John Zimmer、Feike Sijbesma、Emily Leproust が参加して浮上しています。
Van Grieken 氏は、この資金により、チームはデータ収集をスケールアップし、機械学習に関してはより良いデータ収集が可能になり、製品を「よりセルフサービス」にするために取り組むことができると述べました。
「私たちの目標は、バイオベースの製品を市場に出すためのコストと時間を 1 桁削減することです」と van Grieken はプレス リリースで述べています。市場へのバイオベースの製品。」