AI によって生成された音楽は、すでに十分に革新的なコンセプトですが、Riffusion は、オーディオではなく、 画像 オーディオの。
奇妙に聞こえますが、奇妙です。 しかし、それが機能する場合は機能します。 そして、それはうまくいきます! すこし。
Diffusion は、昨年 AI の世界に大きな影響を与えた画像を生成するための機械学習手法です。 DALL-E 2 と Stable Diffusion は、視覚的なノイズを、プロンプトがどのように見えるべきであると AI が考えるものに徐々に置き換えることによって機能する、最も知名度の高い 2 つのモデルです。
この方法は多くの状況で強力であることが証明されており、微調整の影響を非常に受けやすくなっています。つまり、ほとんどトレーニングされたモデルに特定の種類のコンテンツを多く与えて、そのコンテンツのより多くの例を生成することに特化させることができます。 たとえば、水彩画や車の写真で微調整することができ、それらのいずれかを再現する能力が高いことが証明されます.
Seth Forsgren と Hayk Martiros が趣味のプロジェクト Riffusion で行ったことは、スペクトログラムの Stable Diffusion を微調整することでした。
「Hayk と私は一緒に小さなバンドを組んでいます。私たちがプロジェクトを始めたのは、単に音楽が好きで、オーディオに変換するのに十分な忠実度を持つスペクトログラム イメージを Stable Diffusion で作成できるかどうかさえわからなかったからです」と Forsgren は言います。 TechCrunchに語った。 「これまでのすべてのステップで、私たちは何が可能であるかにますます感銘を受け、1 つのアイデアが次のアイデアにつながりました。」
スペクトログラムとは何ですか? それらは、時間の経過に伴うさまざまな周波数の振幅を示すオーディオの視覚的表現です。 時間の経過とともにボリュームを示し、オーディオを一連の山と谷のように見せる波形を見たことがあるでしょう。 総音量だけでなく、ローエンドからハイエンドまでの各周波数の音量を表示したと想像してみてください。
これは私が作った曲の一部です(シークレット・マシーンズの「マルコーニのラジオ」、疑問に思っている場合):
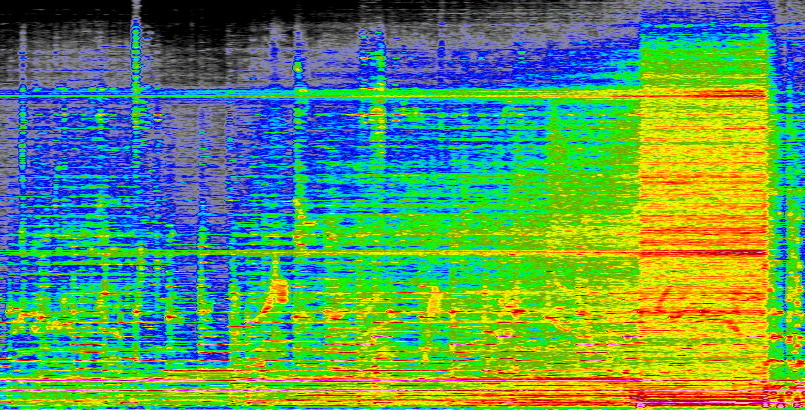
画像クレジット: デヴィン・コールドウィー
曲が構築されるにつれて、すべての周波数で音量が大きくなることがわかります。また、何を探すべきかを知っていれば、個々の音符や楽器を見つけることさえできます。 このプロセスは本質的に完璧でも無損失でもありませんが、正確で体系的な音の表現です。 そして、同じプロセスを逆に実行することで、サウンドに戻すことができます。
Forsgren と Martiros は、多数の音楽のスペクトログラムを作成し、結果の画像に「ブルース ギター」、「ジャズ ピアノ」、「アフロビート」などの関連用語をタグ付けしました。 このコレクションをモデルに与えることで、特定のサウンドが「どのように見えるか」、およびそれらをどのように再作成または結合するかについての良いアイデアが得られました。
画像を調整しながらサンプリングすると、拡散プロセスは次のようになります。

画像クレジット: セス・フォースグレン / ヘイク・マルティロス
実際、このモデルはスペクトログラムを生成できることが証明されており、サウンドに変換すると、「ファンキー ピアノ」や「ジャジー サックス」などのプロンプトに非常によく一致します。 次に例を示します。

画像クレジット: セス・フォースグレン / ヘイク・マルティロス
しかしもちろん、正方形のスペクトログラム (512 x 512 ピクセル、標準の Stable Diffusion 解像度) は短いクリップのみを表します。 3 分間の曲は、はるかに広い長方形になります。 一度に 5 秒間音楽を聴きたい人はいませんが、作成したシステムの制限により、高さ 512 ピクセル、幅 10,000 ピクセルのスペクトログラムを作成することはできませんでした。
いくつかのことを試した後、彼らは大量の「潜在空間」を持つ Stable Diffusion のような大規模モデルの基本構造を利用しました。 これは、より明確に定義されたノード間のノーマンズ ランドのようなものです。 猫を表すモデルの領域と犬を表す別の領域がある場合のように、それらの「間に」あるのは潜在的な空間であり、AI に描画するように指示した場合、何らかの犬猫または猫犬になります。そのようなこと。
ちなみに、潜在空間のものはそれよりもずっと奇妙になります:
ただし、Riffusion プロジェクトには不気味な悪夢のような世界はありません。 代わりに、「教会の鐘」と「エレクトロニック ビート」のような 2 つのプロンプトがある場合、一度に少しずつステップを踏むと、徐々に驚くほど自然にフェードアウトすることがわかりました。ビートでも:
それは奇妙で興味深い音ですが、明らかに特に複雑でも高忠実度でもありません。 覚えておいてください、彼らは拡散モデルがこれを行うことができるかどうかさえ確信していませんでした.
より長い形式のクリップを生成することは可能ですが、まだ理論的です:
「コーラスとヴァースが繰り返されるクラシックな 3 分間の曲を実際に作成しようとしたことはありません」と Forsgren 氏は言います。 「曲の構造について上位レベルのモデルを構築し、個々のクリップに対して下位レベルのモデルを使用するなど、いくつかの巧妙なトリックで実現できると思います。 または、完全な曲のより大きな解像度の画像を使用して、モデルを深くトレーニングすることもできます。」
ここからどこへ行くのですか? 他のグループは、さまざまな方法で AI 生成音楽を作成しようとしています。 音声合成モデル ダンスディフュージョンのような特別に訓練されたオーディオのものに。
Riffusion は、音楽を再発明するための壮大な計画というよりも、「うわー、これを見て」というデモのようなものであり、Forsgren と Martiros は、人々が自分の仕事に従事し、楽しんで、それを繰り返しているのを見ることができてうれしかったと言いました。
「ここから進むべき方向はたくさんあり、その過程で学び続けることに興奮しています。 今朝、私たちのコードの上に他の人がすでに独自のアイデアを構築しているのを見るのも楽しかったです。 Stable Diffusion コミュニティの驚くべき点の 1 つは、元の作成者が予測できない方向性で、人々が物事の上に構築する速さです。」
次のライブ デモでテストできます。 リフュージョン.com、ただし、クリップがレンダリングされるまで少し待つ必要があるかもしれません — これは、クリエイターが予想していたよりも少し注目を集めました. コードはすべて利用可能です Aboutページから、そのためのチップを持っている場合は、自由に実行してください。