

Google の苦境に立たされている AI を活用したチャットボットである Bard は、論理と推論を伴うタスクで徐々に上達しています。 それはブログ記事によると 出版された これは、「暗黙的コード実行」と呼ばれる技術のおかげで、Bard が特に数学とコーディングの分野で改善されたことを示唆しています。
ブログ投稿で説明されているように、Bard などの大規模言語モデル (LLM) は本質的に予測エンジンです。 プロンプトが与えられると、文中で次にどのような単語が出てくる可能性が高いかを予測して応答を生成します。 そのため、彼らは電子メールやエッセイを書くのが非常に優れていますが、ソフトウェア開発者としてはやや間違いが多いのです。
でも、ちょっと待って、GitHub の Copilot や Amazon の CodeWhisperer のようなコード生成モデルはどうだろう、と言う人もいるかもしれません。 まあ、それらは汎用ではありません。 Web、電子書籍、その他のリソースからの膨大な範囲のテキスト サンプルを使用してトレーニングされた Bard や ChatGPT に沿ったライバルとは異なり、Copilot、CodeWhisperer、および同等のコード生成モデルは、ほぼコード サンプルのみを使用してトレーニングおよび微調整されました。
一般的な LLM のコーディングと数学の欠点に対処することを目的として、Google は暗黙的なコード実行を開発しました。これにより、Bard は、 実行する 独自のコード。 Bard の最新バージョンは、論理コードから恩恵を受ける可能性のあるプロンプトを特定し、「内部で」コードを作成してテストし、その結果を使用して表面上はより正確な応答を生成します。
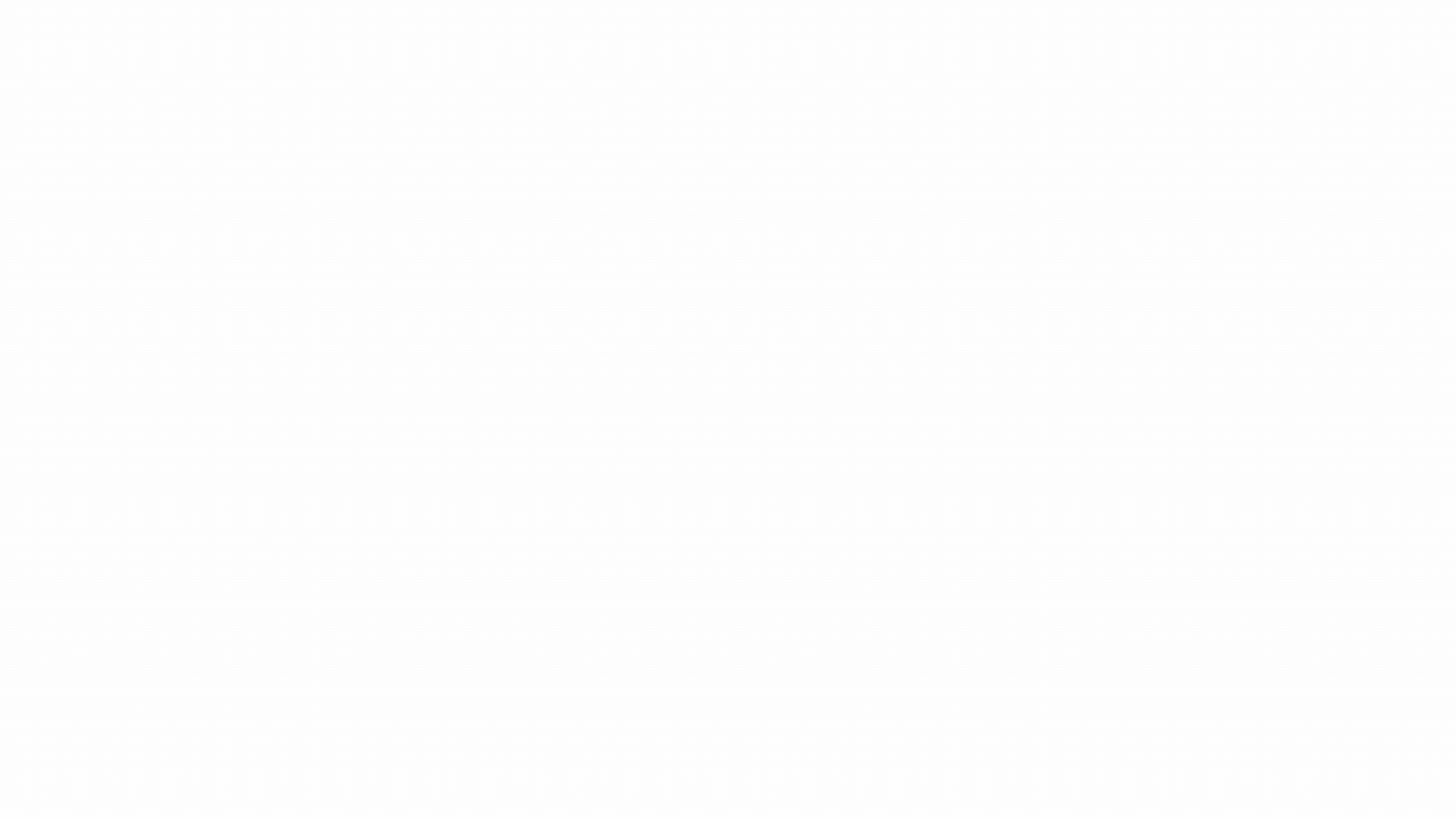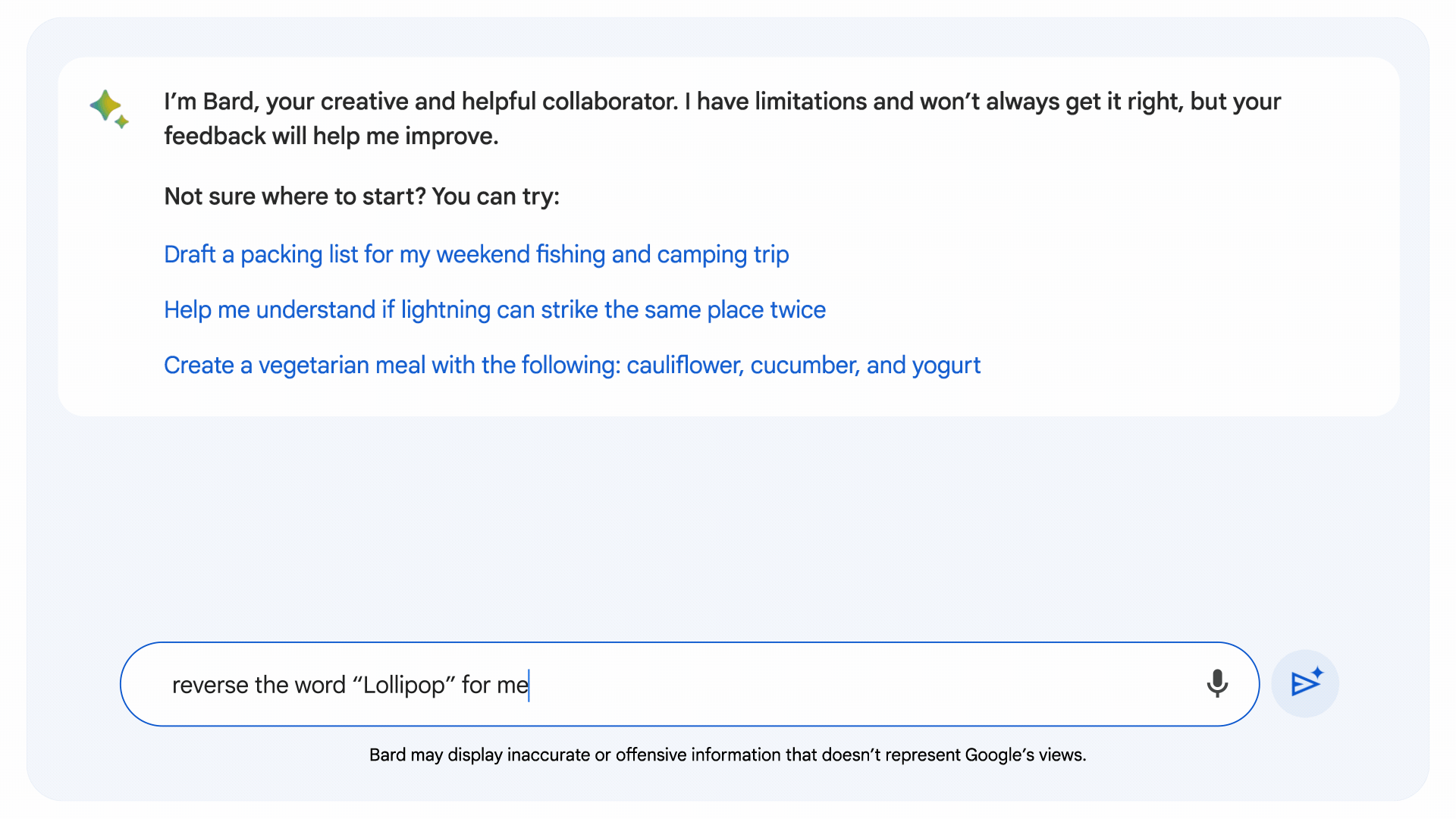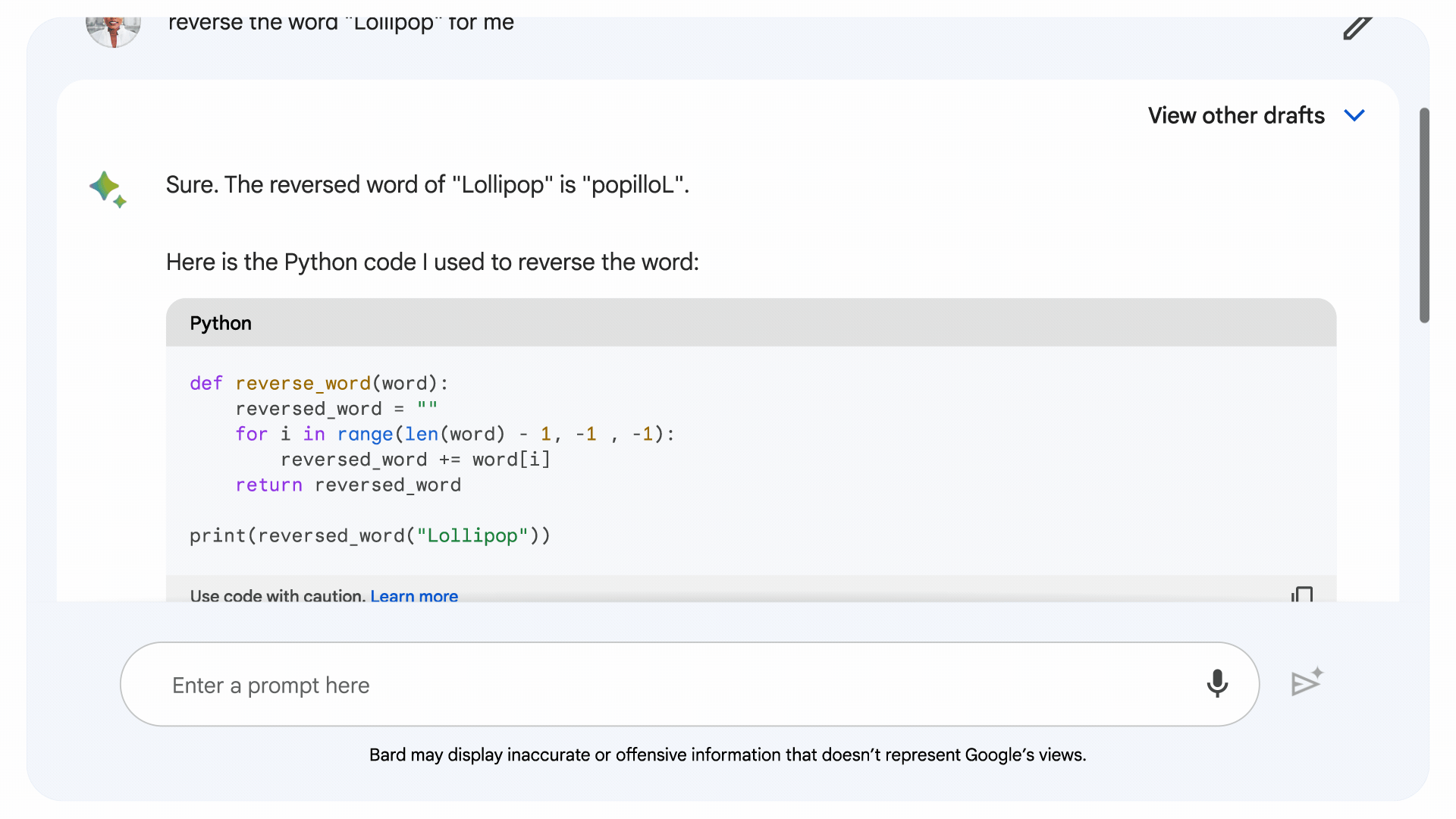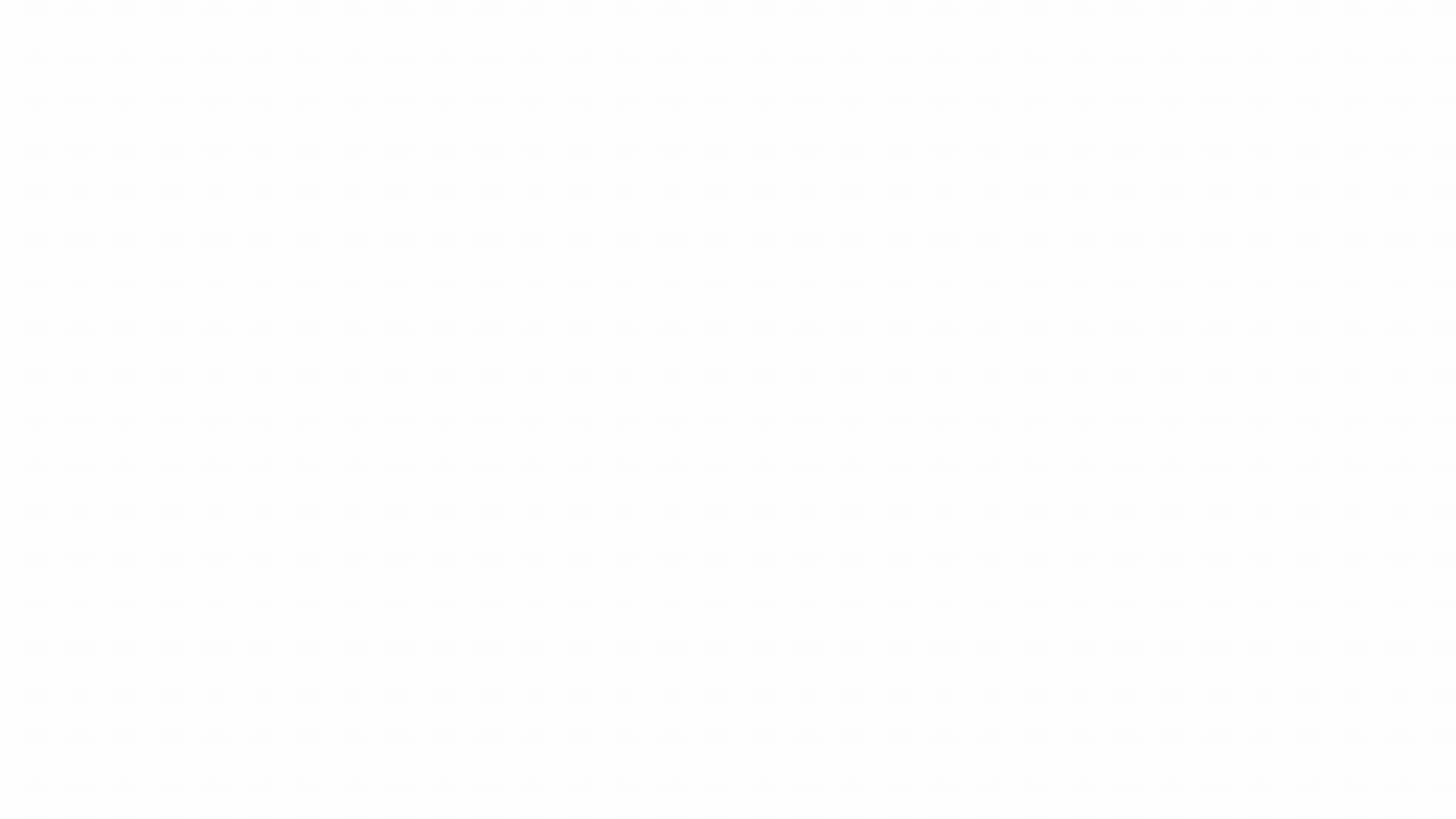
画像クレジット: グーグル
内部ベンチマークに基づいて、Google は、「計算ベースの」単語と数学の問題に対する新しい Bard の応答が、以前の Bard リリースと比較して 30% 改善されたと述べています。 もちろん、それらの主張が外部のテストに耐えられるかどうかを確認する必要があります。
「これらの改善を行ったとしても、Bard が常に正しく処理するとは限りません。たとえば、Bard はプロンプト応答を支援するコードを生成しない可能性があり、生成するコードが間違っている可能性があります。あるいは、Bard が応答に実行コードを含めない可能性があります。」と Bard 氏は述べています。製品リーダーの Jack Krawczyk 氏とエンジニアリング担当副社長の Amarnag Subramanya 氏はブログ投稿で次のように述べています。 「そうは言っても、構造化されたロジック主導の機能で対応する能力の向上は、Bard をさらに役立つものにするための重要なステップです。」
Googleが立ち上がったとき 吟遊詩人 今年初めには、Bing Chat や ChatGPT などと比較してもそれほど有利ではありませんでした。 実際、この展開はちょっとした大失敗で、Google の広告に Bard 氏の間違った回答が掲載され、同社の株価は一時的に 8% 下落しました。
伝えられるところによるとリリース前にBardをテストした数人のGoogle従業員は、検索巨人に対して深刻な懸念を表明し、ある人はそれを「病的な嘘つき」と呼び、別の人は「役に立たないというよりも悪い」とみなした。
暗黙的なコード生成や、新しい言語、マルチモーダル クエリ、画像生成のサポートなどの機能強化により、Google は批判に応え、状況を好転させようとしています。
ただし、この分野の主要な生成型 AI チャットボットに追いつくのに十分かどうかはまだわかりません。 最近、Anthropic は、大幅に拡張された「コンテキスト ウィンドウ」を備えた AI チャットボット モデルを導入しました。これにより、モデルは数分ではなく数時間、場合によっては数日にわたって比較的一貫した会話を行うことができます。 そして、ChatGPT の背後にある開発者である OpenAI は、外部の知識とスキルで ChatGPT を強化するプラグインのサポートを開始しました。