
に続いて レポートの詳細 Twitterがかつて偶然に行った方法 陰謀論者を許可した バードウォッチとして知られる招待者のみの事実確認プログラムに参加し、今日、同社は 発表 このプログラムは、いくつかの変更を加えて、全米のユーザーに拡大されます。 この展開により、米国の中間選挙に先立って、このプログラムに毎週 1,000 人以上の貢献者が追加されます。 しかし、Birdwatch は以前と同じようには機能しないだろう、と Twitter は述べています。
以前は、Birdwatch の寄稿者はすぐにファクト チェックを追加して、ツイートに追加のコンテキストを提供することができました。 今、その特権を獲得する必要があります。
ツイートに「メモ」または追加のコンテキストを提供する注釈を書き込むことができるバードウォッチの寄稿者になるには、まず、他の人が書いた役立つメモを特定できることを証明する必要があります。
これを判断するために、Twitter は各潜在的な貢献者に「評価への影響」スコアを割り当てます。 このスコアは 0 から始まり、バードウォッチの寄稿者になるには「5」に達する必要があります。これは、1 週間の作業の後に達成できる可能性が高い指標です、と Twitter は述べています。 ユーザーは、メモが「役に立った」または「役に立たなかった」のステータスを獲得できるようにするバードウォッチのメモを評価することで、これらのポイントを獲得します。 評価がメモの最終ステータスとは対照的に終わると、ポイントを失います。
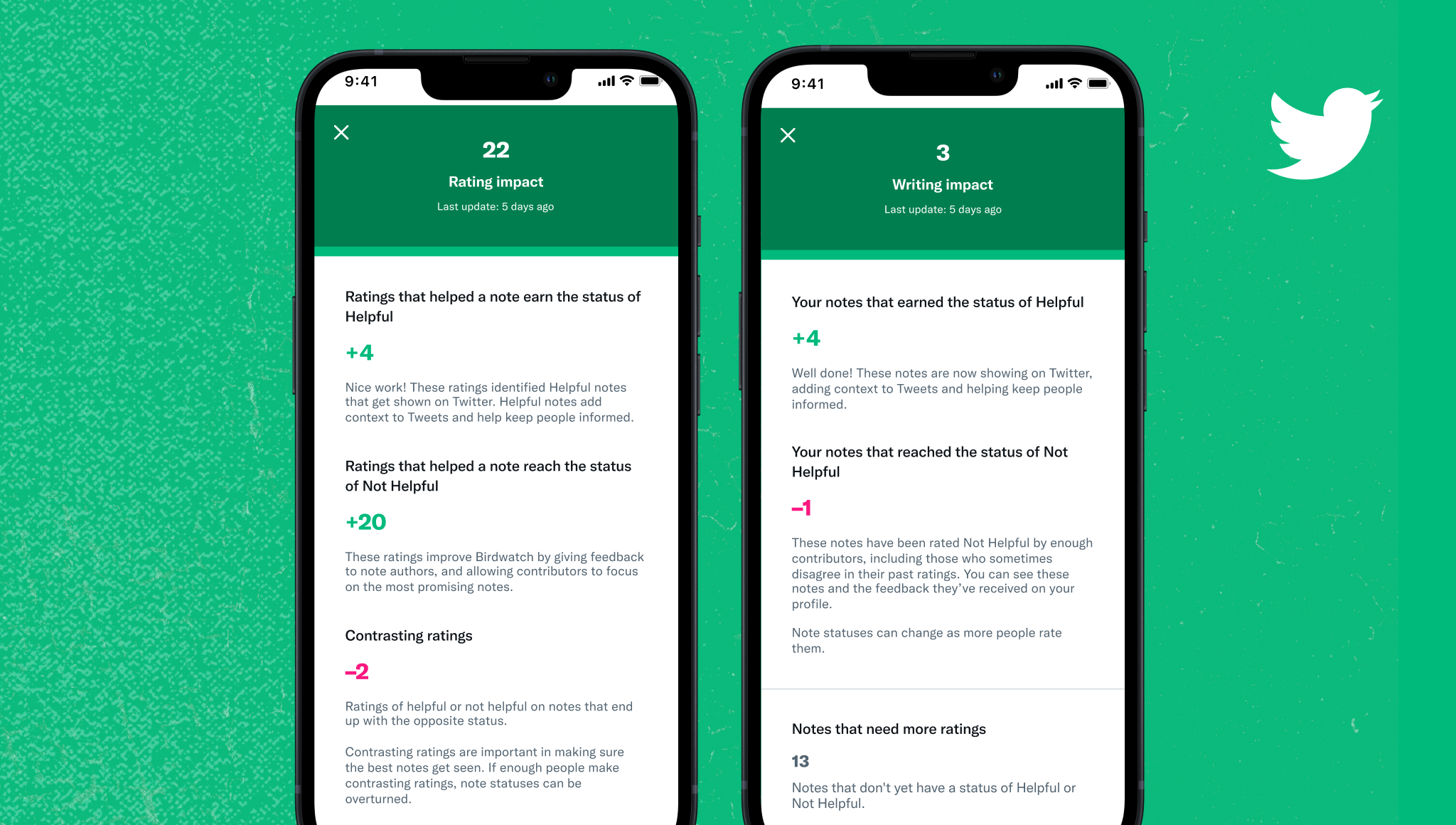
画像クレジット: ツイッター
人が自分のバードウォッチ メモを書く能力のロックを解除した後、貢献とファクト チェックを追加し始めることができます。 しかし、彼らの仕事の質が原因で、再び寄稿者の地位を失う可能性があります。
Twitter はまず、メモが「役に立たなかった」とマークされているユーザーに改善を促します。たとえば、ツイートの主張に適切に対処したり、タイプミスを修正したりします。 しかし、それでも上達しないと、書く能力がロックされてしまいます。 その後、再び投稿者になるには、評価の影響スコアを改善する必要があります。
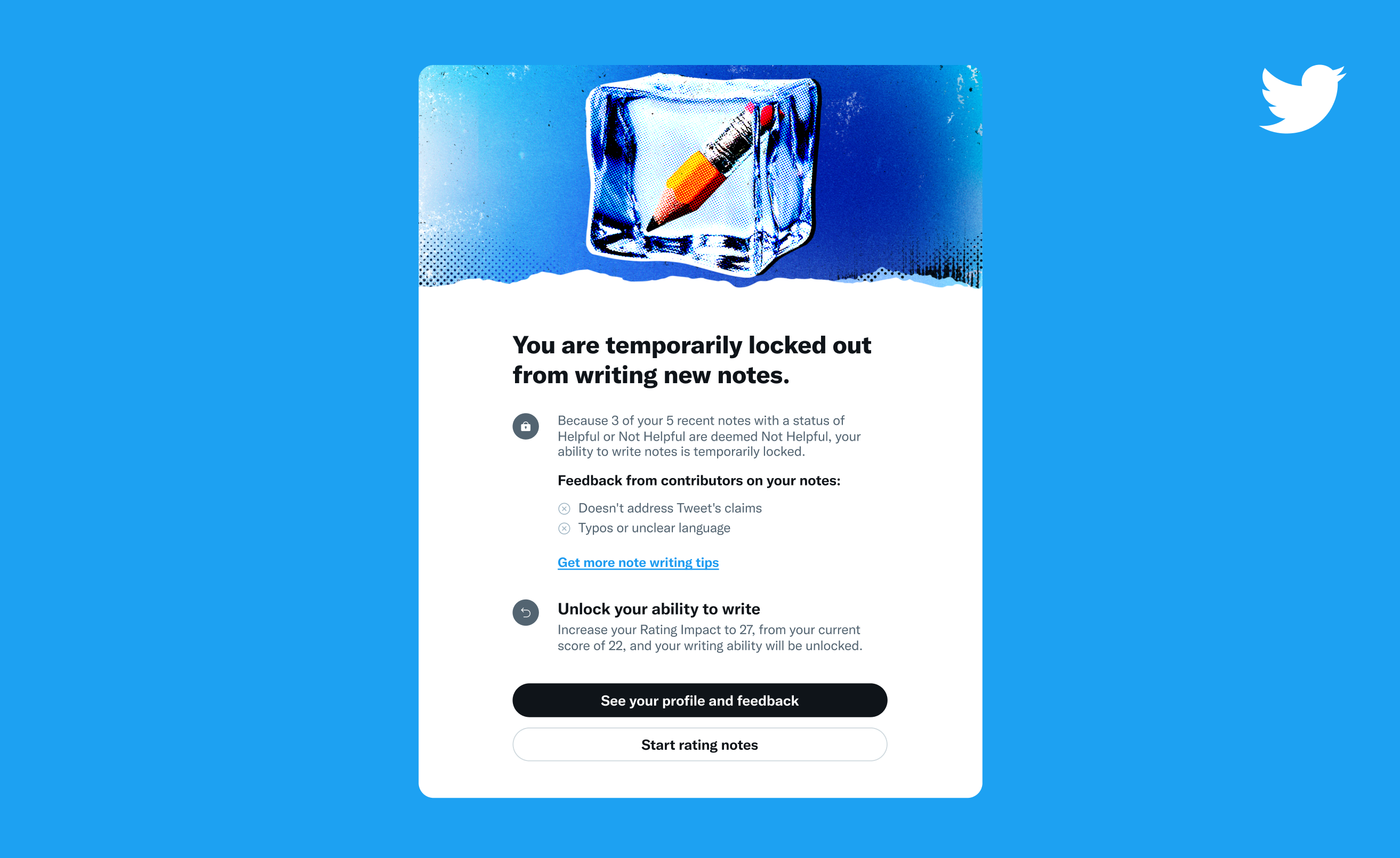
画像クレジット: ツイッター
もう 1 つの重要な側面は、Birdwatch のアップグレードされたシステムに、同社が「ブリッジング アルゴリズム」と呼んでいるものをどのように使用するかということです。
これは、多くのソーシャル メディア アルゴリズムとは異なる動作をする、と Twitter は述べています。 多くの場合、インターネット アルゴリズムは、過半数のコンセンサスがあるかどうかに基づいて、どのコンテンツを高く評価または承認するかを決定します。 または、プラットフォームは、エンゲージメントの特定のしきい値を満たす投稿を考慮する場合があります。 決定する どの投稿がフィードに追加されるか。
一方、Twitter のブリッジング アルゴリズムは、その代わりに、プラットフォーム上の他のユーザーにクラウドソーシングによるファクト チェックを強調する前に、通常は異なる視点を持つグループ間でコンセンサスを見つけようとします。
「ツイートに表示されるメモは、歴史的にレーティングに反対してきた人々にとって実際に役立つものである必要があります」と、Twitter プロダクト VP の Keith Coleman 氏は記者団とのブリーフィングで説明しました。 彼によると、メモについて意見が分かれがちな人が、特定のメモが役立つことに同意する場合、他の人もそのメモの重要性について同意する可能性が高くなるということです。
「これは斬新なアプローチです。 これが以前に行われた他の分野については知りません」とコールマンは言いました。
ただし、Twitter はこのアイデアを発明したわけではありません。 むしろ、この概念は、インターネットの分極化に関する学術研究から生まれました。そこでは、ブリッジング アルゴリズムのアイデア、または ブリッジベースのランキング、複数の真実が共存しているように見える世界で、より良いコンセンサスを作成するための潜在的なアプローチであると考えられています. 今日、双方は自分たちの「真実」だけが真実であり、他方は嘘であると主張しているため、合意を見つけるのが困難になっています. ブリッジング アルゴリズムは、両側が一致する領域を探します。 理想的には、プラットフォームは、さらなる分裂を生み出す投稿に報酬を与えるのではなく、「分裂を橋渡しする」行動に報酬を与えるでしょう。
バードウォッチ ノートの場合、Twitter は、パイロット テスト中にこの新しいスコアリング システムに切り替えてから、すでに影響が見られると主張しています。
誤解を招く可能性のあるツイートについてのメモを読んだ後、その内容に同意する可能性は平均で 20% から 40% 低いことがわかりました。
コールマン氏は、これは「トピックの理解を変えるという観点から非常に重要です」と述べています。
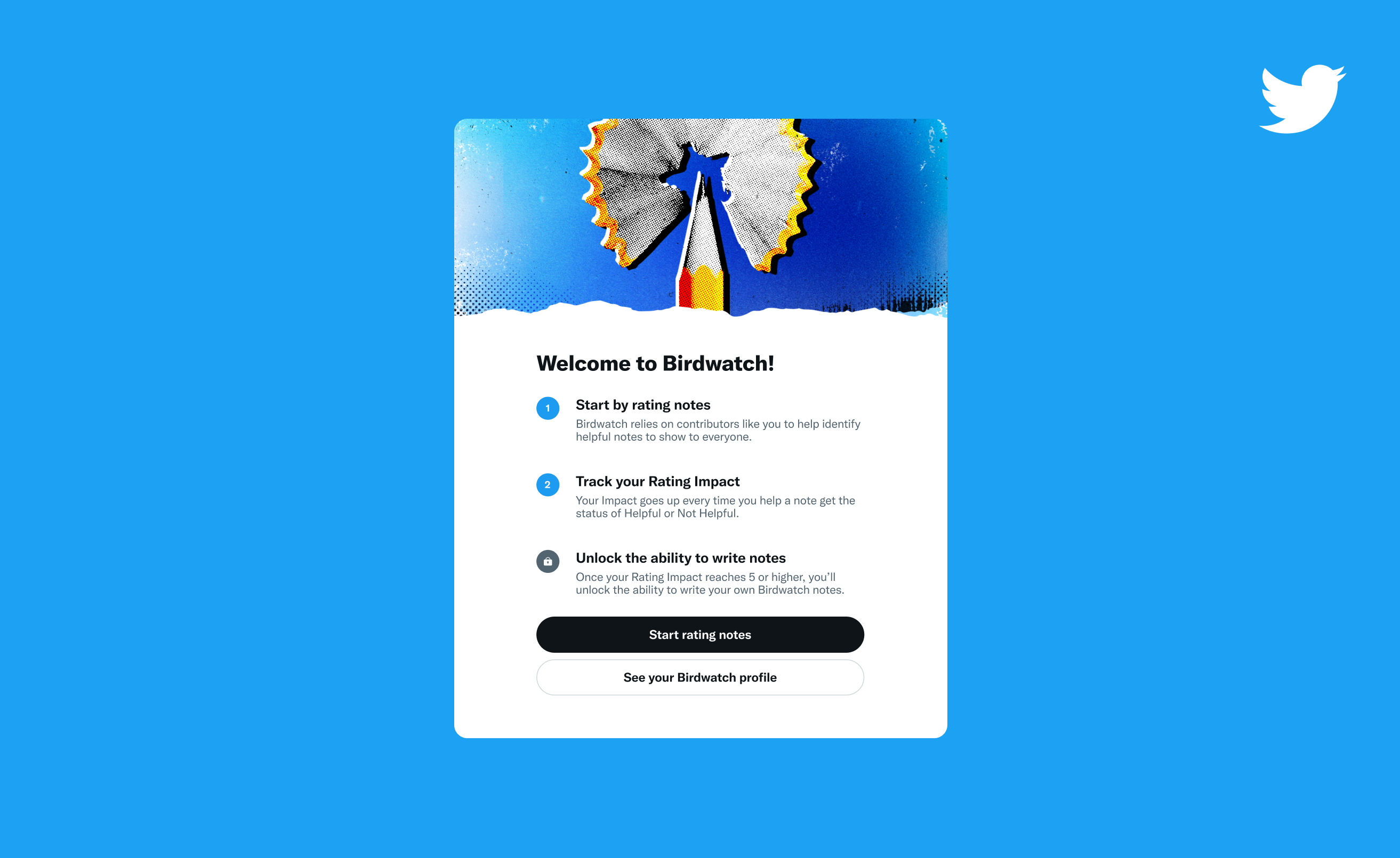
画像クレジット: ツイッター
さらに、システムは党派を超えて合意を見つけるように機能すると、Twitter は主張しています。 民主党、無所属、共和党の間で、この測定値に「統計的に有意な差はない」と述べた。
もちろん、これは、通路を横断する合意に依存している場合、実際に野生に出現するバードウォッチノートがどれだけあるかという疑問を投げかけます.
結局のところ、2 つの真実はありません。 がある の 真実と、相手が真実として提示したいもの。 そして、この方程式の両側に多くの人々がいて、それぞれが自分と同じように考える他の人が投票する情報を持っています (または、バードウォッチの場合のように、役に立ったまたは役に立たなかった)。 これは、インターネットがもたらした問題です。デジタル ソープボックスで最も大きな声が最も注目される群衆を支持して、専門知識と経験が割り引かれるシステムの 1 つです。
バードウォッチは、事実に基づいて共通点を見つけるため、クラウドソーシングによるファクトチェッカーによって高められた特定の点について人々が合意に達すると信じていますが、これは最終的には、Politifact や Snopes などのファクトチェック組織が約束したのと同じ約束です。 しかし、彼らが明らかにした事実が一方が信奉していた物語と一致していなかったとき、負けたチームの人々はシステム全体が腐敗していると指摘した.
バードウォッチが同様の運命をどれくらいの期間逃れるかは不明です。
しかしTwitterは、選挙の誤った情報に対抗するためにBirdwatchをより広く展開するつもりはないと述べている。 システムがスケールする準備ができていると信じているだけです。
さらに、同社は、Birdwatch を使用して、政治以外のあらゆる種類の誤解を招くコンテンツや誤った情報に取り組むことができると述べています。これには、健康、スポーツ、エンターテイメント、インターネット上に現れるその他のランダムな好奇心などの分野が含まれます。 人間ほどの大きさのコウモリの写真をツイートした、 例えば。
また、パイロット段階で、Twitter は、Birdwatch のメモが添付されたツイートをいいねまたはリツイートする可能性が 15% から 35% 低いことを発見しました。
「これは、理解に情報を与えるだけでなく、これらのバードウォッチのメモが人々の共有行動にも情報を与えているという、本当に心強い兆候です」とコールマンは指摘しました。
画像クレジット: ツイッター
Twitter が Birdwatch システムを微調整したのはこれが初めてではありません。 テストを開始して以来、寄稿者がメモを残すときに情報源を引用するよう促し、ユーザーが嫌がらせや虐待の可能性を最小限に抑えるためにエイリアスでメモを投稿できるようにするプロンプトを追加しました. また、ノートを読んだ人の数をユーザーに知らせる通知も追加されました。
また、Twitter 全体のユーザーがメモを評価できるようになりましたが、これらの評価によってメモの利用可能性の結果が変わることはありません。Birdwatch の寄稿者による評価だけが影響します。
AP や Reuters などの同社のパートナーは、Twitter がメモの正確さを確認するのを支援しますが、Birdwatch に何が表示されるかは決定されません。 これはコンセンサスの分散システムであり、トップダウンの取り組みではありません。 ただし、Twitter によると、このプロジェクトを 18 か月にわたって試験運用してきた間、「役に立った」とマークされたメモは、パートナーも正確であると判断したものであるとのことです。
さらに、Birdwatch アルゴリズムとシステムへのすべての貢献は公開されており、誰でもアクセスできるように GitHub でオープン ソース化されています。
Twitter によると、Birdwatch は約 15,000 人の寄稿者で試験運用されていますが、今後毎週約 1,000 人の寄稿者を追加してプログラムの規模を拡大し始める予定です。 米国内であれば誰でも資格を得ることができますが、追加は先着順となります。 メモは英語とスペイン語の両方で書くことができますが、これまでのところ、ほとんどが英語で書くことを選択しています.
潜在的なボットと戦うために、Birdwatch の寄稿者は、仮想番号ではなく、携帯電話会社から確認済みの電話番号も取得する必要があります。 アカウントに最近のルール違反がなく、少なくとも 6 か月経過している必要があります。
米国のユーザーベースの約半数は、今日から「役に立った」ステータスに達したバードウォッチのメモも見始めます。
Twitter は、新しいシステムは、独自のファクト チェック ラベルや誤報ポリシーに取って代わるものではなく、連携して実行することを意図していると述べています。
今日、同社の誤報ポリシーは、市民の誠実さからCOVID、健康に関する誤った情報、操作されたメディアなど、さまざまなトピックをカバーしています.
「これら以外にも、誤解を招く可能性のあるコンテンツがまだたくさんあります」と Coleman 氏は述べています。 ツイートは事実に基づいている可能性がありますが、さらなるコンテキストを提供し、誰かがそのトピックをどのように理解したかに影響を与える詳細を省略する可能性があると彼は示唆しました. 「それに対するポリシーはありません。これらの灰色の領域でポリシーを作成するのは非常に困難です」と Coleman 氏は続けました。
「Birdwatch の強みの 1 つは、あらゆるつぶやき、グレーゾーンをカバーできることです。 そして最終的には、コンテキストが追加されるのに十分役立つかどうかを決定するのは人々次第です」と彼は言いました.