
機械学習とAIの分野での研究は、現在、事実上すべての業界と企業の主要なテクノロジーであり、誰もがすべてを読むにはあまりにも膨大です。 このコラム、パーセプトロンは、特に人工知能に限定されないが、最も関連性の高い最近の発見と論文のいくつかを収集し、それらが重要である理由を説明することを目的としています。
最近のこの一連の調査では、Metaは、200の異なる言語を「最先端の」結果で翻訳できる最初の言語システムであると主張する言語システムをオープンソース化しました。 負けないように、Googleは機械学習モデルを詳しく説明しました。 ミネルバ、それは数学的および科学的な質問を含む定量的な推論の問題を解決することができます。 そしてマイクロソフトは言語モデルをリリースしました、 ゲーデル、Googleで広く知られているLamdaに沿った「現実的な」会話を生成するため。 そして、ひねりを加えた新しいテキストから画像へのジェネレータがいくつかあります。
Metaの新しいモデルであるNLLB-200は、世界のほとんどの言語で機械を利用した翻訳機能を開発するという同社のNo LanguageLeftBehindイニシアチブの一部です。 カンバ語(バントゥー民族グループが話す)やラオス語(ラオスの公用語)などの言語、および以前の翻訳システムでは十分にサポートされていない、またはまったくサポートされていない540以上のアフリカ言語を理解するように訓練されたNLLB-200は、 Metaは最近、Wikimedia Foundationのコンテンツ翻訳ツールに加えて、FacebookNewsFeedとInstagramで言語を翻訳すると発表しました。
AIの翻訳は、大幅に拡張できる可能性があります—そしてすでに もっている スケーリング–人間の専門知識がなくても翻訳できる言語の数。 しかし、一部の研究者が指摘しているように、システムは主にインターネットからのデータでトレーニングされているため、誤った用語、省略、誤訳にまたがるエラーがAIで生成された翻訳に現れる可能性があります。すべてが高品質であるとは限りません。 たとえば、Google翻訳では、医師は男性、看護師は女性であると想定されていましたが、Bingの翻訳者は、「テーブルは柔らかい」などのフレーズをドイツ語で女性の「ダイタベル」(図の表を参照)として翻訳しました。
NLLB-200の場合、Metaは、データクリーニングパイプラインを「主要なフィルタリング手順」と200言語のフルセットの毒性フィルタリングリストで「完全にオーバーホール」したと述べました。 それが実際にどれほどうまく機能するかはまだわかりませんが、NLLB-200の背後にいるメタ研究者が彼らの方法を説明する学術論文で認めているように、バイアスが完全にないシステムはありません。
同様に、Godelは、Webからの膨大な量のテキストでトレーニングされた言語モデルです。 ただし、NLLB-200とは異なり、ゲーデルは「オープンな」対話、つまりさまざまなトピックに関する会話を処理するように設計されています。
画像クレジット: マイクロソフト
ゲーデルは、レストランについての質問に答えたり、近所の歴史や最近のスポーツゲームなどの特定の主題について前後に対話したりすることができます。 便利なことに、GoogleのLamdaと同様に、システムは、レストランのレビュー、ウィキペディアの記事、その他の公開Webサイトのコンテンツなど、トレーニングデータセットの一部ではなかったWeb全体のコンテンツを利用できます。
しかし、ゲーデルはNLLB-200と同じ落とし穴に遭遇します。 論文の中で、それを作成する責任のあるチームは、それを訓練するために使用されたデータの「社会的偏見および他の毒性の形態」のために「有害な反応を引き起こす可能性がある」と述べています。 これらのバイアスを排除する、あるいは軽減することさえ、AIの分野では未解決の課題であり、完全には解決されない可能性があります。
Googleのミネルバモデルは潜在的に問題が少ないです。 その背後にあるチームがブログ投稿で説明しているように、システムは、計算機などの外部ツールを使用せずに定量的推論の問題を解決するために、数式を含む118GBの科学論文とWebページのデータセットから学習しました。 ミネルバは、数値計算と「記号操作」を含むソリューションを生成でき、人気のあるSTEMベンチマークで最高のパフォーマンスを実現します。
ミネルバは、これらのタイプの問題を解決するために開発された最初のモデルではありません。 いくつか例を挙げると、AlphabetのDeepMindは、複雑で抽象的なタスクで数学者を支援できる複数のアルゴリズムを示しました。OpenAIは 実験 小学校レベルの数学の問題を解決するために訓練されたシステムで。 しかし、ミネルバは数学的な質問をよりよく解決するために最近の技術を取り入れている、とチームは言います。新しい質問を提示する前に、既存の質問に対するいくつかの段階的な解決策でモデルを「促す」ことを含むアプローチを含みます。

画像クレジット: グーグル
ミネルバは依然として間違いをかなりの割合で行っており、正しい最終的な答えに到達することもありますが、推論に誤りがあります。 それでも、チームは、それが「科学と教育のフロンティアを推進するのに役立つ」モデルの基盤として役立つことを望んでいます。
AIシステムが実際に「知っている」という質問は、技術的なものよりも哲学的ですが、その知識をどのように編成するかは、公正で関連性のある質問です。 たとえば、オブジェクト認識システムは、飼い猫とトラがそれらを識別する方法で概念を意図的に重複させることにより、いくつかの点で類似していることを「理解」していることを示す場合があります。生き物はそれとはまったく関係がありません。
UCLAの研究者は、言語モデルがその意味で単語を「理解」しているかどうかを確認したいと考えていました。 「セマンティックプロジェクション」と呼ばれる方法を開発しました。。 クジラが魚とどのように、そしてなぜ違うのかをモデルに説明するように単純に求めることはできませんが、クジラがそれらの単語を他の単語とどの程度密接に関連付けているかを確認できます。 哺乳類、 大きい、 はかり、 等々。 クジラが哺乳類との関連性が高く、鱗とは関連性がない場合は、クジラが何について話しているのかについて適切な考えを持っていることがわかります。
モデルによって概念化されたように、動物が小から大のスペクトルに分類される例。
簡単な例として、彼らは動物がサイズ、性別、危険、および湿りの概念と一致しているのに対し(選択は少し奇妙でした)、州は天気、富、および党派と一致していることを発見しました。 動物は無党派であり、州はジェンダーレスであるため、すべてのトラックがあります。
モデルがいくつかの単語を理解するかどうかについては、それらを描画するように依頼するよりも確実なテストは今のところありません。テキストから画像へのモデルは改善され続けています。 Googleの「PathwaysAutoregressiveText-to-Image」またはPartiモデルは、これまでで最高のモデルの1つに見えますが、アクセスできない競合他社(DALL-E et al。)と比較することは困難です。これは、一部のモデルが提供するものです。 。 とにかく、ここでPartiアプローチについて読むことができます。
Googleの記事の興味深い側面の1つは、モデルがパラメーターの数を増やしてどのように機能するかを示していることです。 数字が増えるにつれて画像が徐々に改善する様子をご覧ください。

プロンプトは「オレンジ色のパーカーと青いサングラスをかけたカンガルーがシドニーオペラハウスの前の芝生に立って、胸にウェルカムフレンズと書かれた看板を持っているポートレート写真」でした。
これは、最高のモデルがすべて数百億のパラメーターを持っていることを意味しますか?つまり、スーパーコンピューターでのみトレーニングして実行するのに何年もかかることを意味しますか? 今のところ、確かに—それは物事を改善するための強引なアプローチのようなものですが、AIの「カチカチ」は、次のステップが単にそれをより大きく、より良くすることではなく、より小さく、同等にすることを意味します。 誰がそれをうまくやってのけるのかを見ていきます。
Metaは今週、生成AIモデルを披露しましたが、それを使用するアーティストにより多くのエージェンシーを与えると主張しています。 これらのジェネレーターを自分でたくさん遊んだことがあるので、楽しみの一部はそれが何を思いつくかを見ることですが、彼らはしばしば無意味なレイアウトを思い付くか、プロンプトを「取得」しません。 MetaのMake-A-Sceneは、それを修正することを目的としています。
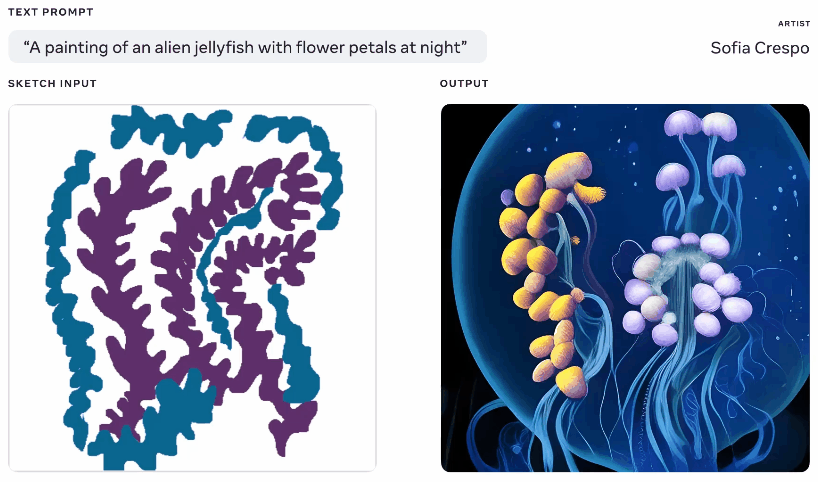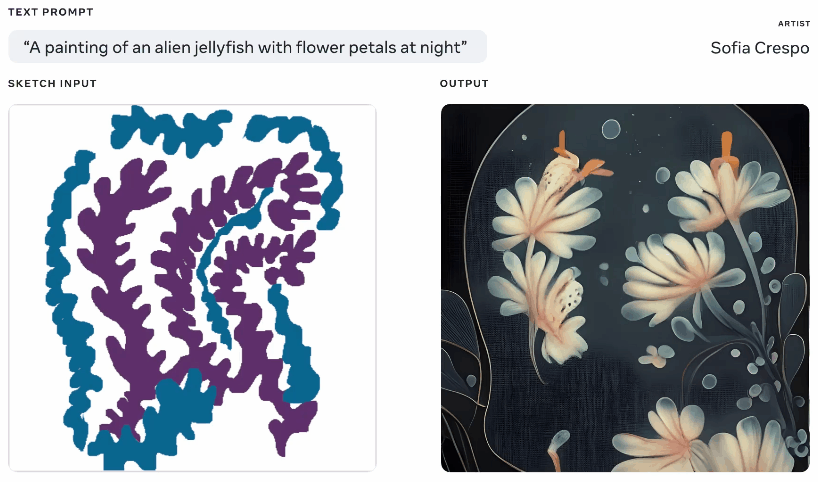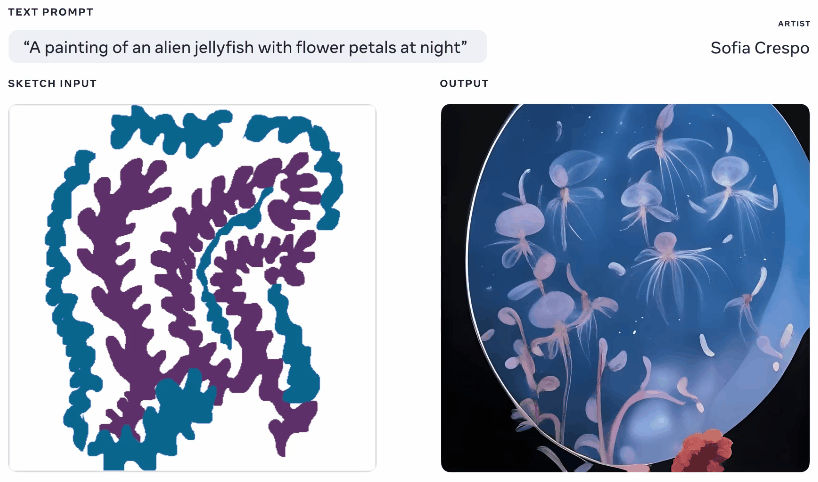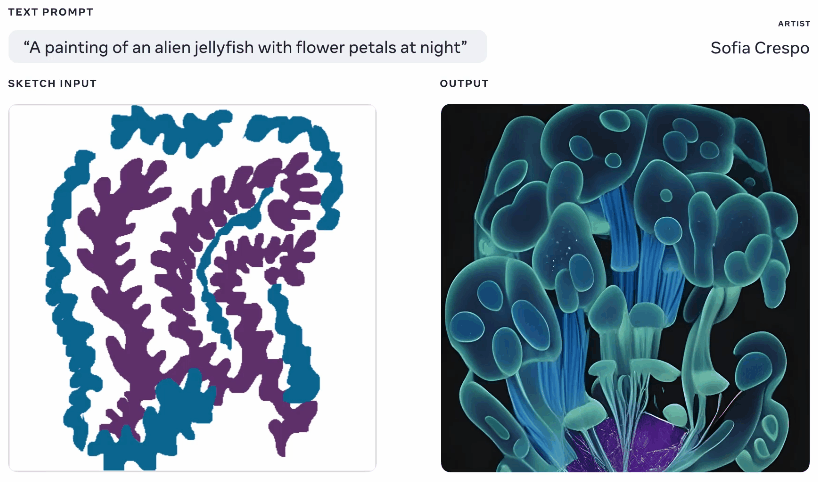
同じテキストとスケッチプロンプトから生成されたさまざまな画像のアニメーション。
これはまったく独創的なアイデアではありません。話している内容の基本的なシルエットでペイントし、それを上に画像を生成するための基盤として使用します。 Googleの悪夢のジェネレーターで2020年にこのようなものを見ました。 これは同様の概念ですが、スケッチをベースとしてテキストプロンプトからリアルな画像を作成できるようにスケールアップされていますが、解釈の余地がたくさんあります。 自分が何を考えているかについて一般的な考えを持っているが、モデルの無制限で奇妙な創造性を含めたいアーティストに役立つ可能性があります。
これらのシステムのほとんどと同様に、Make-A-Sceneは実際には公開されていません。他のシステムと同様に、計算に関してはかなり貪欲だからです。 心配しないでください、私たちはすぐに家でこれらのもののまともなバージョンを手に入れるでしょう。