
データ サイエンティストとして訓練を受けた Jae Lee にとって、TikTok、Vimeo、YouTube などのプラットフォームの台頭により、動画は私たちの生活の大きな部分を占めるようになりましたが、技術的な障壁のために検索が難しいということはまったく理解できませんでした。文脈理解によってもたらされる。 動画のタイトル、説明、タグの検索は常に簡単で、必要なのは基本的なアルゴリズムだけでした。 しかし、検索 内部 特定の瞬間やシーンのビデオは、特にそれらの瞬間やシーンが明白な方法でラベル付けされていない場合、技術の能力をはるかに超えていました.
この問題を解決するために、Lee はテクノロジー業界の友人たちと協力して、動画を検索して理解するためのクラウド サービスを構築しました。 となりました 12 のラボ、ベンチャーキャピタルで1,700万ドルを調達し、そのうち1,200万ドルは本日クローズしたシード延長ラウンドからのものでした。 Radical Ventures は、Index Ventures、WndrCo、Spring Ventures、Weights & Biases の CEO である Lukas Biewald などの参加を得て拡張を主導した、と Lee は TechCrunch にメールで語った。
「Twelve Labs のビジョンは、最も強力なビデオ理解インフラストラクチャを提供することで、開発者が私たちと同じように世界を見て、聞いて、理解できるプログラムを構築できるようにすることです」と Lee 氏は述べています。
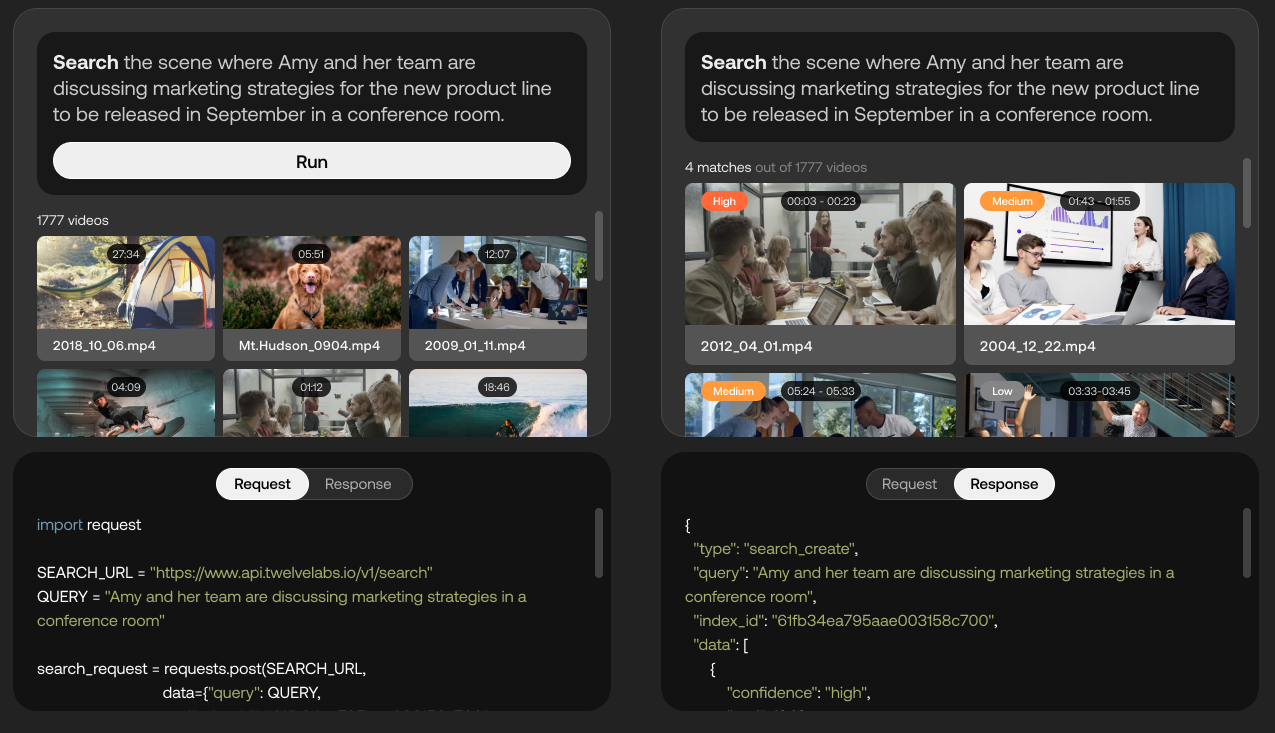
Twelve Labs プラットフォームの機能のデモ。 画像クレジット: 12 のラボ
現在クローズド ベータ版である Twelve Labs は、AI を使用して、動きとアクション、オブジェクトと人、音、画面上のテキスト、スピーチなどのビデオから「豊富な情報」を抽出して、それらの間の関係を識別しようとします。 このプラットフォームは、これらのさまざまな要素を「ベクトル」と呼ばれる数学的表現に変換し、フレーム間の「時間的接続」を形成して、ビデオ シーン検索などのアプリケーションを可能にします。
「開発者がインテリジェント ビデオ アプリケーションを作成するのを支援するという同社のビジョンを達成する一環として、Twelve Labs チームは、マルチモーダル ビデオ理解のための『基礎モデル』を構築しています」と Lee 氏は述べています。 「開発者は一連の API を介してこれらのモデルにアクセスし、セマンティック検索だけでなく、長い形式のビデオの「チャプタライズ」、要約の生成、ビデオの質疑応答などの他のタスクも実行できます。」
Google は、音声、テキスト、ビジュアルに基づいて動画の主題 (「アクリル画材」など) を選択することで、Google 検索と YouTube で動画の推奨を強化するために使用する MUM AI システムを使用して、動画の理解に同様のアプローチを採用しています。コンテンツ。 しかし、技術は同等かもしれませんが、Twelve Labs はそれを市場に出した最初のベンダーの 1 つです。 Google は MUM を内部に保持することを選択し、公開 API を通じて利用できるようにすることを拒否しました。
そうは言っても、Google、Microsoft、Amazon は、動画内のオブジェクト、場所、アクションを認識し、フレーム レベルで豊富なメタデータを抽出するサービス (つまり、Google Cloud Video AI、Azure Video Indexer、AWS Rekognition) を提供しています。 また、フランスのコンピューター ビジョン スタートアップである Reminiz もあり、あらゆる種類のビデオのインデックスを作成し、記録されたコンテンツとライブ ストリーミングされたコンテンツの両方にタグを追加できると主張しています。 しかし、Lee は、Twelve Labs は十分に差別化されていると主張しています。その理由の 1 つは、そのプラットフォームにより、顧客が AI を特定のカテゴリのビデオ コンテンツに合わせて微調整できるからです。

サラダ関連のコンテンツでより適切に機能するようにモデルを微調整するための API のモックアップ。 画像クレジット: 12 のラボ
「私たちが発見したことは、特定の問題を検出するために構築された狭い AI 製品は、制御された設定での理想的なシナリオでは高い精度を示しますが、乱雑な現実世界のデータにはあまりうまくスケーリングしないということです」と Lee 氏は述べています。 「それらはルールベースのシステムとして機能するため、差異が発生したときに一般化する機能が不足しています。 これは、コンテキストの理解の欠如に根ざした制限とも考えられます。 文脈を理解することで、人間は現実世界の一見異なる状況を一般化する独自の能力を得ることができ、これこそが Twelve Labs の唯一の強みです。」
Lee 氏によると、Twelve Labs のテクノロジーは、検索以外にも、広告の挿入やコンテンツのモデレートなどを促進し、たとえばナイフを映している動画が暴力的なものか、それとも教育的なものかをインテリジェントに判断できます。 また、メディア分析やリアルタイムのフィードバックにも使用でき、ビデオからハイライト リールを自動的に生成することもできます。
設立から 1 年余り (2021 年 3 月)、Twelve Labs には有料の顧客がいて (リーは正確な数は明らかにしていません)、Oracle のクラウド インフラストラクチャを使用して AI モデルをトレーニングする複数年契約を Oracle と結んでいます。 今後、スタートアップは技術の構築とチームの拡大に投資する予定です。 (Lee は現在の Twelve Labs の従業員数を明らかにすることを拒否しましたが、LinkedIn データ 約18人であることを示しています。)
「ほとんどの企業にとって、大規模なモデルを通じて得られる大きな価値にもかかわらず、これらのモデルを自分たちでトレーニング、運用、維持することは本当に意味がありません。 Twelve Labs プラットフォームを活用することで、どの組織でも、いくつかの直感的な API 呼び出しで強力なビデオ理解機能を活用できます」と Lee 氏は述べています。 「AI イノベーションの将来の方向性は、マルチモーダル ビデオ理解に向かって真っ直ぐ進んでおり、Twelve Labs は 2023 年にその境界をさらに押し上げる好位置につけています。」