
誰もが他人の声で説得力のあるオーディオを作成できるようになり、多くの人々が緊張しています。 AIに似てる 透かし生成音声の提案 1つでは解決できないかもしれませんが、正しい方向への一歩です.
AI によって生成された音声は、スクリーン リーダーから声優の置き換えまで (もちろん許可を得て)、あらゆる種類の正当な目的に使用されています。 しかし、ほぼすべてのテクノロジーと同様に、音声生成も悪意のある目的に向けられ、政治家や有名人による偽の引用が作成される可能性があります。 広報担当者や綿密な聞き取りに依存せずに、本物と偽物を見分ける方法を見つけることが非常に望ましい.
透かしは、画像または音声に、その起源を示す識別可能なパターンを刻印する技術です。 画像のロゴのような明らかな透かしを見たことはありますが、すべてがそれほど目立つわけではありません。
画像では、隠れた透かしがピクセル単位のレベルでパターンを隠し、人間の目には画像が変更されていないように見えますが、コンピューターには識別可能です。 音声についても同様です。情報をエンコードする時折の静かな音は、何気なく聞いている人には聞こえないかもしれません。
これらの微妙な透かしの問題は、メディアにわずかな変更を加えただけでも消えてしまう傾向があることです。 画像のサイズを変更しますか? ピクセルパーフェクトなコードがあります。 ストリーミング用にオーディオをエンコードしますか? 秘密のトーンは圧縮されて存在しなくなります。
Resemble AI は、微調整された音声モデルを使用して、吹き替え、オーディオブック、および通常は通常の人間の声によって生成されるその他のメディアを生成することを目指している生成 AI スタートアップの新しいコホートの 1 つです。 しかし、おそらく俳優が提供する何時間にもわたる音声で訓練されたそのようなモデルが悪意のある手に渡った場合、これらの企業はPR災害の中心にいることに気づき、おそらく深刻な責任を負う可能性があります. したがって、彼らの録音を可能な限り現実的にする方法と、AI によって生成されたものとして簡単に検証できる方法を見つけることは、彼らにとって非常に興味深いことです。
PerTh は、この目的のために Resemble が提案した透かしプロセスであり、「知覚的」と「しきい値」のぎこちない組み合わせです。
「機械学習モデルを使用して、データのパケットを生成する音声コンテンツに埋め込み、そのデータを後で復元する追加のセキュリティ層を開発しました」と、同社はテクノロジを説明するブログ投稿に書いています。 「データは知覚できないため、音声情報と密接に結合されているため、削除するのが難しく、特定のクリップが Resemble によって生成されたかどうかを確認する方法を提供します。 重要なのは、この「透かし」技術は、スピードアップ、スローダウン、MP3 などの圧縮フォーマットへの変換など、さまざまなオーディオ操作にも耐性があることです。」
これは、人間がオーディオを処理する方法の癖に依存しています。これにより、可聴性の高いトーンは、振幅の小さい近くのトーンを本質的に「マスク」します。 したがって、誰かが笑って 5,000 Hz、8,000 Hz、および 9,200 Hz の周波数でピークが生成された場合、数ヘルツ以内で同時に発生する構造化されたトーンに滑り込むことができ、リスナーには多かれ少なかれ知覚できなくなります. しかし、正しく行えば、オーディオの重要な部分に非常に近いため、除去に対しても堅牢になります。
ここに図があります:
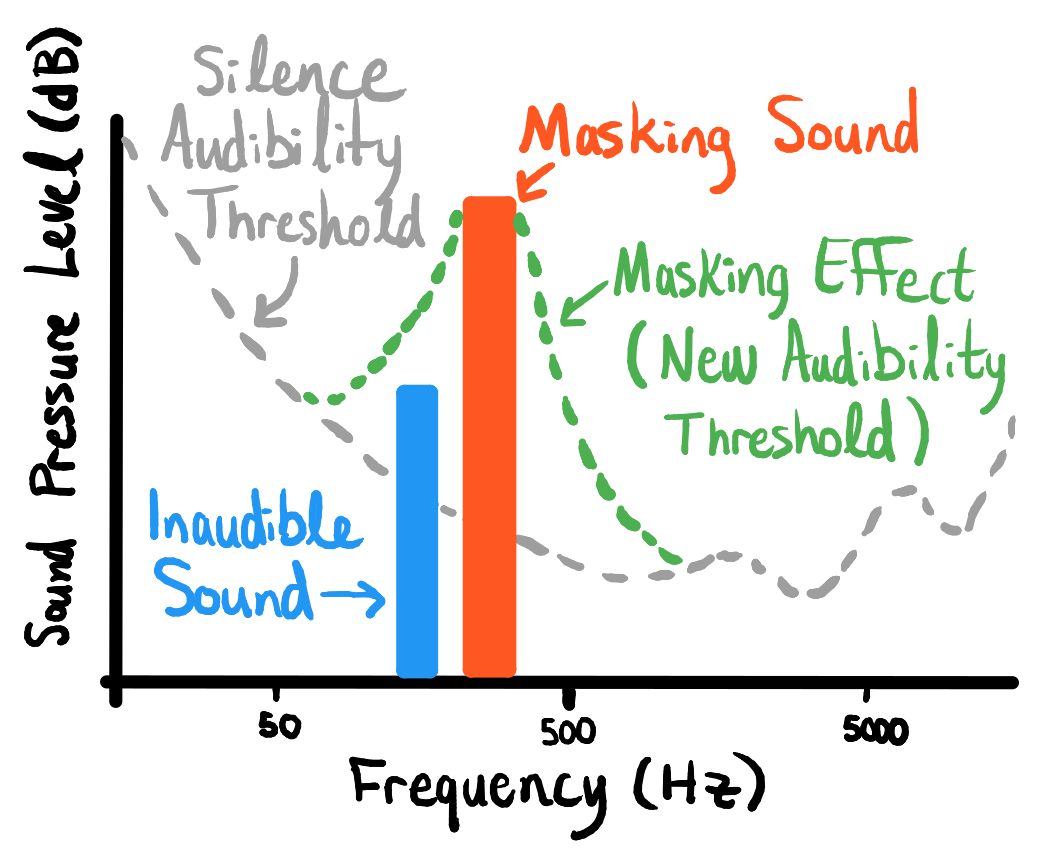
低いトーンが近くのピークによってどのように「マスク」されるかを示す図。
直感的に操作できますが、課題は、候補となる波形セクションを見つけて、識別情報を運ぶ適切でありながら聞こえないオーディオ トーンを自動的に生成できる機械学習モデルを作成することでした。 次に、上記のような一般的なサウンド操作に対する堅牢性を維持しながら、そのプロセスを逆にする必要があります。
彼らが提供した2つの例を次に示します。 透かしが入っているものを把握できるかどうかを確認してください。 ここにカーソルを合わせると、ステータス バーに答えが表示されます。
違いがわからず、波形を細かく調べても明らかな異常は見つかりませんでした。 私は最近、実際にそこに入るほどスペクトル アナライザを使いこなせていませんが、そこから何かが見えるのではないかと思います。 いずれにせよ、Resemble による生成を示すデータがこれらのクリップの 1 つに多かれ少なかれ不可逆的にエンコードされているという主張があれば、それは成功と言えます。
PerTh はまもなく Resemble のすべての顧客に展開されますが、現時点では、同社が生成した音声のみをマークして検出できることは明らかです。 しかし、彼らがそれを行った場合、おそらく他の人もそうするでしょう – そしておそらく、これらのエンジンはすぐに音声生成モデル自体と密接に関連するでしょう. 悪意のあるアクターは常にそのようなことを回避する方法を見つけますが、障壁を設置することで、その行動の一部を抑えることができます。
ただし、オーディオはこのように特殊であり、同様のトリックはテキストや画像には機能しません。 したがって、これらのドメインでは、しばらく不気味の谷にとどまることが予想されます。