
AI のように急速に変化する業界に追いつくのは至難の業です。 そこで、AI がそれをやってくれるようになるまで、機械学習の世界に関する先週の記事と、単独では取り上げなかった注目すべき研究や実験を簡単にまとめておきます。
今週、Google は年次 I/O 開発者カンファレンスで発表したさまざまな新製品で AI ニュース サイクルを独占しました。 彼らは、GitHub の Copilot と競合することを目的としたコード生成 AI から、テキスト プロンプトを短い曲に変換する AI 音楽ジェネレーターまで、幅広い範囲を実行します。
これらのツールのかなりの数は、マーケティング上の単なる単なるものではなく、正当な省力化手段であるように見えます。 私が特に興味をそそられているのは、AI を活用して個人の Google ドキュメント フォルダーにあるファイルを整理、要約、分析するメモ作成アプリ、Project Tailwind です。 しかし、それらは同時に、今日の最高の AI テクノロジーの限界や欠点も明らかにします。
Google の最新の大規模言語モデル (LLM) である PaLM 2 を例に考えてみましょう。 PaLM 2は、OpenAIのChatGPTに対する同社の競合製品であるGoogleの最新のBardチャットツールを強化し、Googleの新しいAI機能のほとんどの基盤モデルとして機能する。 ただし、PaLM 2 は、同等の LLM と同様にコードや電子メールなどを作成できますが、有害で偏った方法で質問に応答することもあります。
Google の音楽ジェネレーターも、実現できることはかなり限られています。 ハンズオンで書いたように、MusicLM で作成した曲のほとんどは、良く言えばまずまず、悪く言えば 4 歳児が夢中になっているように聞こえます。 DAW。
AI がどのように仕事を置き換えるかについては多くのことが書かれています。ある調査によれば、潜在的に 3 億人のフルタイムの仕事に相当する仕事に相当します。 報告 ゴールドマン・サックス著。 で 調査 Harris 氏によると、OpenAI の AI を活用したチャットボット ツールである ChatGPT に慣れている従業員の 40% は、それが自分たちの仕事を完全に置き換えてしまうのではないかと懸念しています。
Google の AI は最終的なものではありません。 確かに、同社の おそらく後ろに AIレースで。 しかし、Google が採用しているのは否定できない事実です。 世界のトップAI研究者の何人か。 そして、これが彼らが対処できる最善のことであるならば、それは AI が解決された問題からはほど遠いという事実の証拠です。
過去数日間の他の注目すべき AI のヘッドラインは次のとおりです。
- Meta は広告に生成 AI をもたらします。 Metaは今週、広告主が代替コピーの作成や、テキストプロンプトによる背景生成、FacebookやInstagram広告の画像トリミングを支援する、ある種のAIサンドボックスを発表した。 同社は、この機能は現時点では一部の広告主のみが利用できるが、7月にはさらに多くの広告主が利用できるよう拡大する予定だと述べた。
- 追加されたコンテキスト: Anthropic は、Claude (主力のテキスト生成 AI モデル (まだプレビュー段階)) のコンテキスト ウィンドウを 9,000 トークンから 100,000 トークンに拡張しました。 コンテキスト ウィンドウは追加のテキストを生成する前にモデルが考慮するテキストを指しますが、トークンは生のテキストを表します (たとえば、単語「fantastic」はトークン「fan」、「tas」、「tic」に分割されます)。 歴史的にも現在でも、記憶力の低下はテキスト生成 AI の有用性の妨げとなってきました。 しかし、コンテキスト ウィンドウが大きくなれば状況が変わる可能性があります。
- Anthropic は「憲法上の AI」を宣伝します: Anthropic モデルの唯一の差別化要因は、コンテキスト ウィンドウの拡大だけではありません。 同社は今週、「憲法」で定義された「価値」をAIシステムに吹き込むことを目的とした社内AIトレーニング手法である「憲法AI」について詳しく説明した。 他のアプローチとは対照的に、Anthropic 氏は、憲法上の AI によってシステムの動作が理解しやすくなり、必要に応じて調整が容易になると主張しています。
- 研究用に構築された LLM: 非営利の Allen Institute for AI Research (AI2) は、大規模で成長を続けるオープン ソース ライブラリに追加する、Open Language Model と呼ばれる研究に焦点を当てた LLM をトレーニングする計画を発表しました。 AI2 は、Open Language Model (略して OLMo) を単なるモデルではなくプラットフォームとして捉えています。これにより、研究コミュニティが AI2 が作成した各コンポーネントを利用して、自分たちで使用したり、改善を図ったりできるようになります。
- AI のための新しい基金: AI2 の他のニュースとしては、非営利団体の AI スタートアップ ファンドである AI2 Incubator が、以前の 3 倍の規模 (1,000 万ドルに対して 3,000 万ドル) に再び勢いを増しているということです。 2017年以来、21社がこのインキュベーターを通過し、さらに約1億6,000万ドルの投資と、少なくとも1件の大規模買収を呼び込んだ。XNORは、後にAppleが約2億ドルで買収したAIの高速化および効率化企業だ。
- EU の生成 AI に関する導入ルール: 欧州議会での一連の投票で、欧州議会議員は今週、OpenAIのChatGPTのような生成型AI技術を支えるいわゆる基礎モデルの要件を定めることなど、欧州連合のAI法案に対する多数の修正案を支持した。 この修正により、基礎モデルのプロバイダーには、モデルを市場に出す前に安全性チェック、データガバナンス対策、リスク軽減を適用する責任が課せられます。
- ユニバーサル翻訳者: Google は、ビデオを新しい言語で再ダビングしながら、話者の唇を決して話さなかった言葉と同期させる、強力な新しい翻訳サービスをテストしています。 これはさまざまな理由で非常に役立つ可能性がありますが、同社は悪用の可能性とそれを防ぐために講じられた手順について率直に述べていました。
- 自動説明: OpenAI の ChatGPT に沿った LLM はブラック ボックスであるとよく言われますが、確かにそれにはある程度の真実があります。 それらの層を剥がす努力の中で、OpenAI は 現像 LLM のどの部分がどの動作に関与しているかを自動的に識別するツール。 これを担当するエンジニアは、まだ初期段階にあると強調しているが、これを実行するコードは今週の時点で GitHub のオープンソースで入手できる。
- IBM が新しい AI サービスを開始します。 IBMは年次Thinkカンファレンスで、AIモデルを構築し、コンピューターコードやテキストなどを生成するための事前トレーニング済みモデルへのアクセスを提供するツールを提供する新しいプラットフォームであるIBM Watsonxを発表しました。 同社は、この立ち上げの動機は、職場内で AI を導入する際に多くの企業が依然として経験している課題にあると述べています。
その他の機械学習
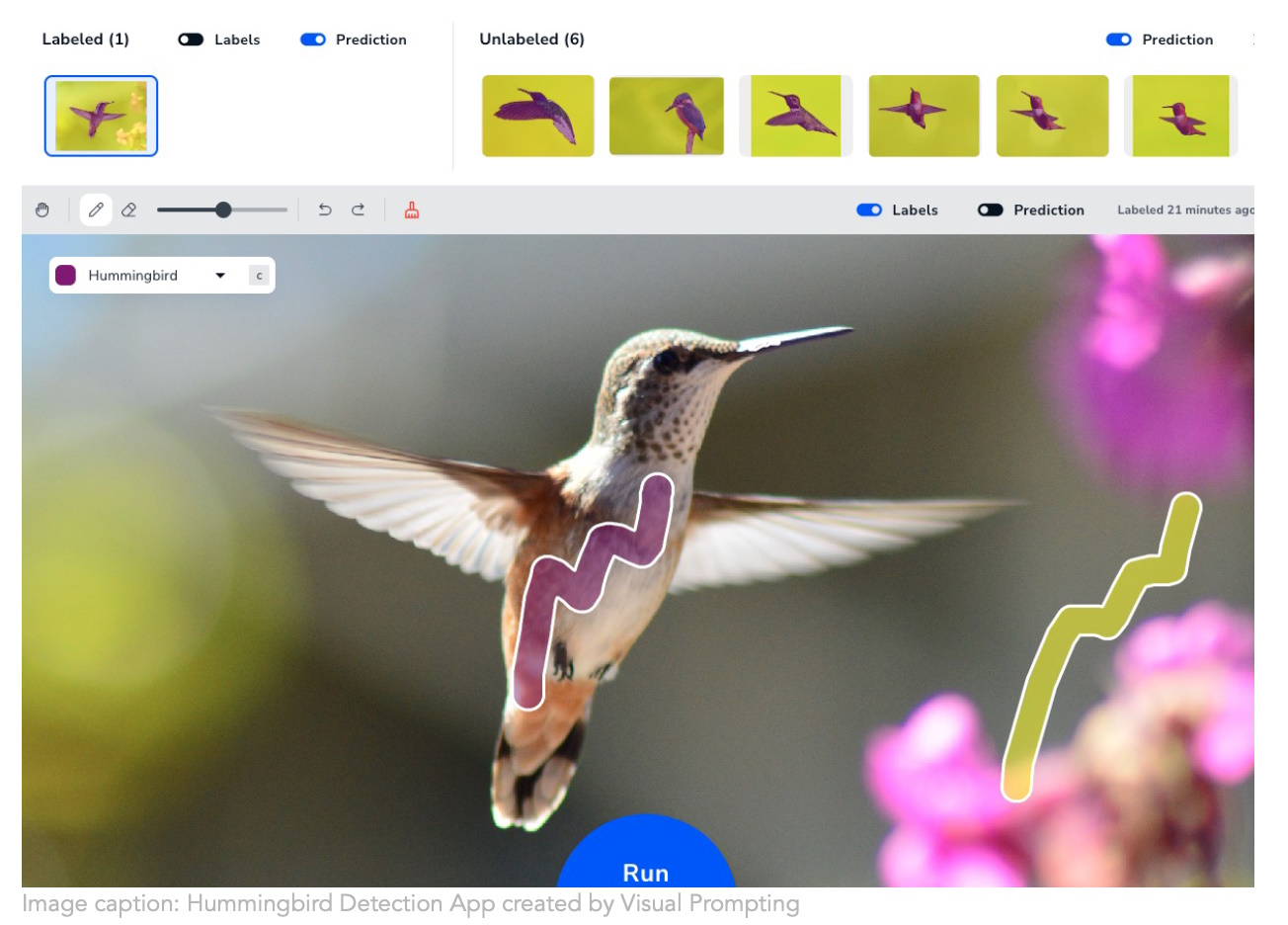
画像クレジット: 着陸AI
アンドリュー・ンの新しい会社 着陸AI は、コンピュータ ビジョン トレーニングを作成するために、より直感的なアプローチを採用しています。 画像内で何を識別したいのかをモデルに理解させるのはかなり骨の折れる作業ですが、 彼らの「視覚的プロンプト」テクニック ブラシ ストロークを数回行うだけで、そこから意図を理解します。 セグメンテーション モデルを構築する必要がある人は誰でも、「やっとできた!」と言っています。 おそらく現在、細胞小器官や家庭用品のマスキングに何時間も費やしている大学院生がたくさんいるでしょう。
マイクロソフトが申請しました ユニークで興味深い方法での拡散モデル、基本的にそれらを使用して画像の代わりにアクションベクトルを生成し、観察された多くの人間のアクションでトレーニングしました。 まだ初期段階にあり、普及はこれに対する明確な解決策ではありませんが、安定していて多用途であるため、純粋に視覚的なタスクを超えてどのように適用できるかを見るのは興味深いです。 彼らの論文は今年後半に ICLR で発表される予定です。
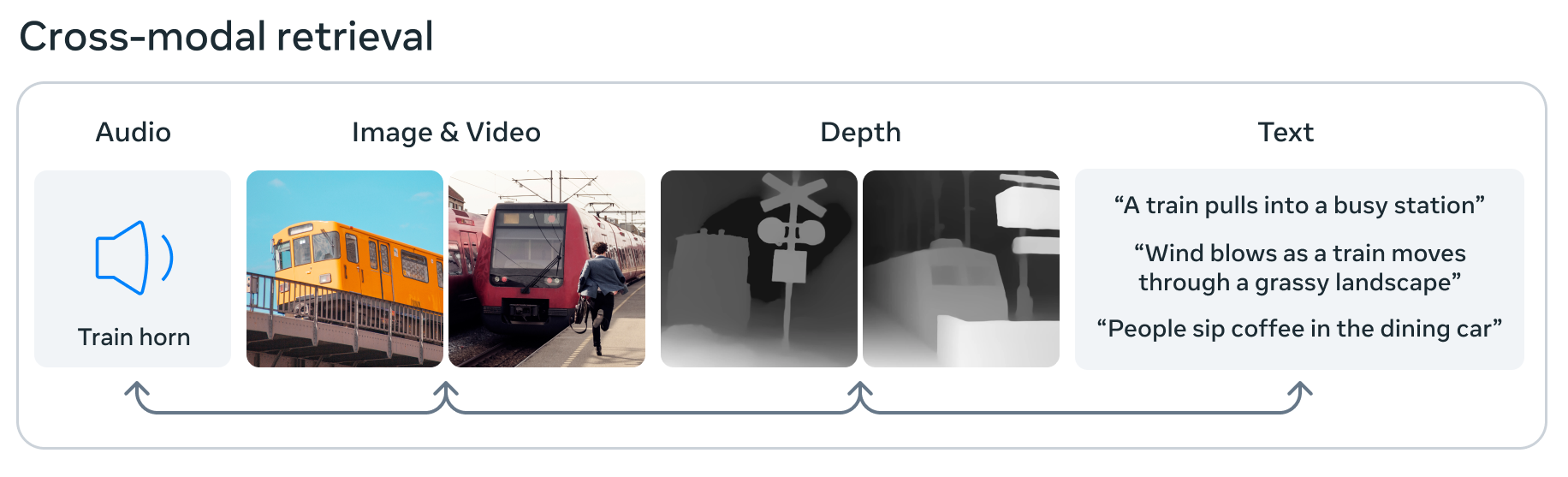
画像クレジット: メタ
メタはまた、AI の最先端を推進しています。 イメージバインドこれは、画像とビデオ、オーディオ、3D 深度データ、熱情報、動きまたは位置データの 6 つの異なるモダリティからのデータを処理および統合できる最初のモデルであると主張しています。 これは、その小さな機械学習埋め込み空間で、画像が音声、3D 形状、およびさまざまなテキストの説明に関連付けられ、そのいずれかについて質問されたり、意思決定に使用されたりする可能性があることを意味します。 これは、脳のようにデータを吸収して関連付けるという点で、「一般的な」AI への一歩です。ただし、まだ基本的で実験段階なので、まだ興奮しすぎないでください。
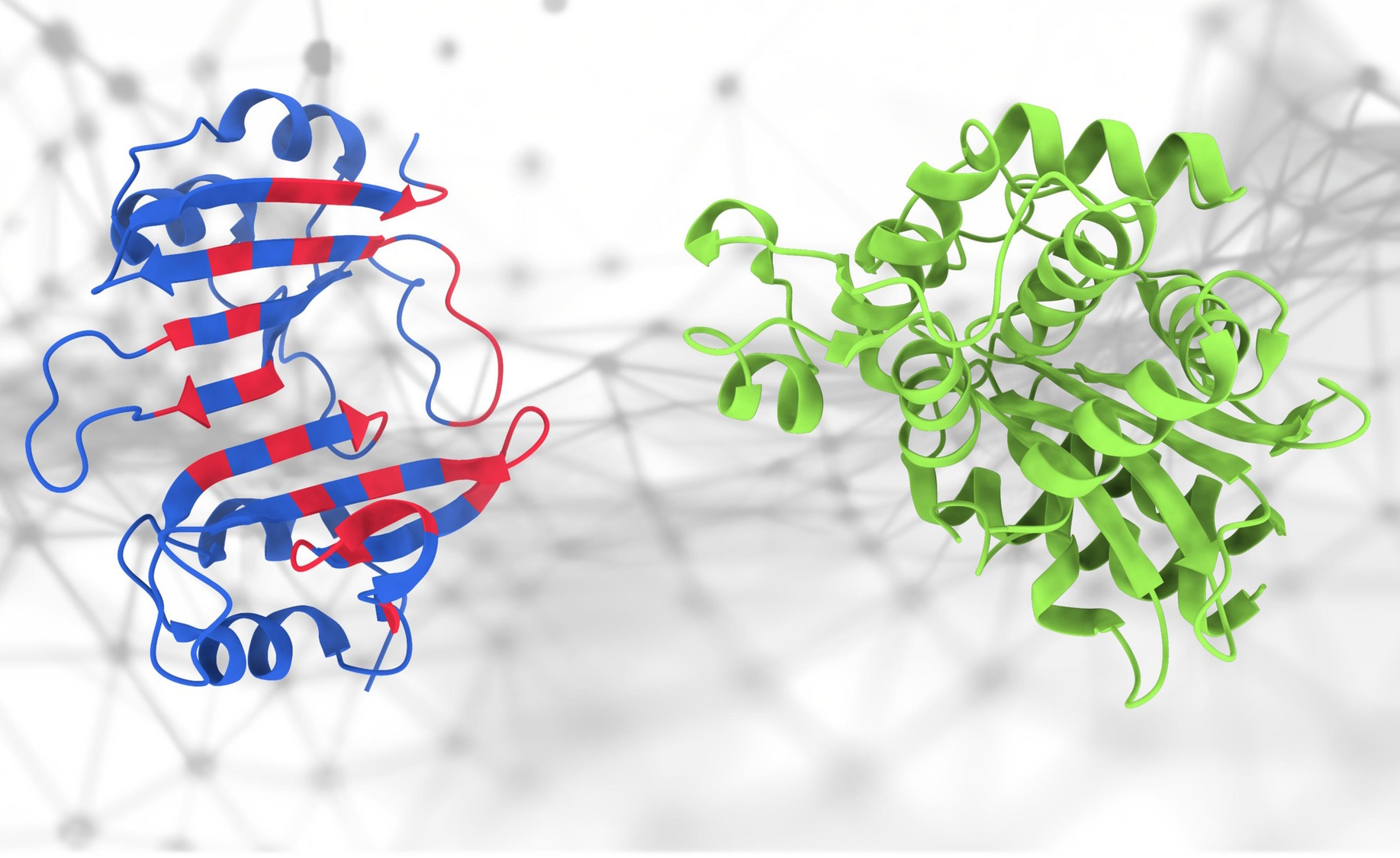
これらのタンパク質が接触すると…何が起こるでしょうか?
誰もが AlphaFold に興奮しましたが、それには正当な理由がありました。しかし実際には、構造はプロテオミクスという非常に複雑な科学のほんの一部にすぎません。 これらのタンパク質がどのように相互作用するかが重要であり、予測するのが難しいのですが、この新しい EPFL の PeSTo モデル まさにそれをやろうとしています。 「タンパク質構造内の重要な原子と相互作用に焦点を当てています」と主任開発者のルシアン・クラップ氏は語った。 「これは、この方法がタンパク質構造内の複雑な相互作用を効果的に捉え、タンパク質結合界面の正確な予測を可能にすることを意味します。」 たとえそれが正確でなくても、100% 信頼できるものではなかったとしても、ゼロから始める必要がないことは、研究者にとって非常に便利です。
連邦政府はAIに大きく取り組んでいます。 大統領も立ち寄りました AI のトップ CEO たちとの面会 これを正しく理解することがいかに重要かを言います。 もしかしたら、多くの企業が必ずしも質問するのに適しているわけではないかもしれませんが、少なくとも検討に値するアイデアをいくつか持っているはずです。 でも、彼らにはすでにロビイストがいますよね?
私はそれよりも興奮しています 連邦政府の資金提供を受けて新たな AI 研究センターが誕生。 OpenAI や Google などが行っている製品中心の研究とのバランスをとるためには、基礎研究が非常に必要です。 社会科学(CMUにて)、または気候変動と農業 (ミネソタ大学にて)、(比喩的にも文字通りにも)緑の野原のように感じます。 これには私もちょっと声を大にして言いたいのですが、 森林計測に関するメタリサーチ。

大画面で一緒に AI を実行する – それは科学です。
AI に関する興味深い会話がたくさんあります。 私は思った UCLA (私の母校、ブルーインズに行きましょう) の学者、ジェイコブ・フォスター氏とダニー・スネルソン氏へのインタビューです。 興味深いものでした。 今週末、人々が AI について話しているときに、あなたが思いついたふりをするのに最適な、LLM についての素晴らしい考えを次に示します。
これらのシステムは、ほとんどの文章が形式的にどの程度一貫しているかを明らかにします。 これらの予測モデルがシミュレートする形式が汎用的であればあるほど、成功率は高くなります。 こうした発展により、私たちはフォームの規範的な機能を認識し、フォームを変革する可能性があることを認識するようになりました。 表現空間を捉えることに非常に優れた写真の導入後、絵画環境は印象派を発展させました。このスタイルは、絵の具自体の物質性を残すために正確な表現を完全に拒否しました。
それは絶対に使ってますよ!