
機械学習と AI の分野の研究は、今やほとんどすべての業界や企業で重要な技術となっていますが、そのすべてを読むには膨大な量の研究が行われています。 このコラム、パーセプトロンは、最も関連性の高い最近の発見と論文のいくつかを収集することを目的としており、特に人工知能に限定されませんが、それらが重要な理由を説明します。
過去数週間、Google の研究者は AI システムのデモを行いました。 パリ、100 以上の言語で多くのタスクを実行できます。 他の場所では、ベルリンを拠点とするグループが、 ソース+ これは、ビジュアル アーティスト、ミュージシャン、ライターなどのアーティストが、自分の作品を AI のトレーニング データとして使用することをオプトインおよびオプトアウトできるようにする方法として設計されています。
OpenAI の GPT-3 のような AI システムは、かなり意味のあるテキストを生成したり、Web、電子ブック、その他の情報源から既存のテキストを要約したりできます。 しかし、歴史的にそれらは 1 つの言語に限定されており、その有用性とリーチの両方が制限されてきました。
幸いなことに、ここ数か月で、Hugging Facial area の Bloom などのコミュニティの取り組みによって、多言語システムの研究が加速しています。 これらの進歩を多言語化に活用する試みとして、Google チームは PaLI を作成しました。PaLI は、画像キャプション、オブジェクト検出、光学式文字認識などのタスクを実行するために、画像とテキストの両方でトレーニングされました。
画像クレジット: グーグル
Google は、PaLI が 109 の言語を理解し、それらの言語の単語と画像の関係を理解できると主張しています。これにより、たとえば、ポストカードの写真にフランス語でキャプションを付けることができます。 作品はしっかりと研究段階にとどまっていますが、クリエイターは、言語と画像の重要な相互作用を示しており、将来的に商用製品の基盤を確立できる可能性があると述べています.
音声は、AI が絶えず改善している言語のもう 1 つの側面です。Play.ht は最近、驚くべき量の感情と範囲を結果に反映させる新しいテキスト読み上げモデルを披露しました。 先週投稿されたクリップ もちろん厳選されていますが、素晴らしいサウンドです。
この記事のイントロを使用して独自のクリップを生成しましたが、結果は依然として堅実です。
このタイプの音声生成が最も役立つ正確な用途はまだ不明です。 私たちは、彼らが本全体を作成する段階にはまだ至っていません。むしろ、可能ですが、まだ最初の選択肢ではないかもしれません。 しかし、品質が向上するにつれて、アプリケーションは倍増します。
Mat Dryhurst と Holly Herndon (それぞれ学者と音楽家) は、組織 Spawning と提携して Source+ を立ち上げた。許可を求めた。 コストがかからない Supply+ は、アーティストが自分の作品を AI トレーニングの目的で使用することを、必要に応じて拒否できるようにすることを目的としています。
Stable Diffusion や DALL-E 2 などの画像生成システムは、テキスト プロンプトをアートに変換する方法を「学習」するために、Web から収集した数十億の画像でトレーニングされました。 これらの画像の一部は、ArtStation や DeviantArt などのパブリック アート コミュニティから提供されたものであり、必ずしもアーティストの知識が必要ではありませんが、特定のクリエイターを模倣する機能をシステムに埋め込んでいます。 含む グレッグ・ルトウスキーのようなアーティスト。

安定拡散からのサンプル。
アート スタイルを模倣するシステムの巧妙さのために、一部のクリエイターは、生計を脅かす可能性があることを恐れています。 Source+ は、自発的ではありますが、アートがどのように使用されるかについてアーティストに大きな発言権を与えるための一歩になる可能性があると、Dryhurst 氏と Herndon 氏は言います — それが大規模に採用されれば (大きな if です)。
DeepMind の研究チームは、 試みている AI のもう 1 つの長年の問題点である、有毒で誤解を招く情報を吐き出す傾向を解決することです。 チームはテキストに焦点を当て、Google を使用して World wide web を検索することで一般的な質問に答えることができる、Sparrow というチャットボットを開発しました。 Google の LaMDA のような他の最先端のシステムでも同じことができますが、DeepMind は、Sparrow が質問に対してもっともらしい、毒性のない回答を他のシステムよりも頻繁に提供すると主張しています。
その秘訣は、システムを人々の期待に合わせることでした。 DeepMind は Sparrow を使用する人を募集し、フィードバックを提供して回答がどれほど有用であるかのモデルをトレーニングし、参加者に同じ質問に対する複数の回答を示し、どの回答が最も気に入ったかを尋ねました。 研究者はまた、「脅迫的な発言をしない」、「憎悪や侮辱的なコメントをしない」などのSparrowのルールを定義し、参加者にだましてルールを破らせようとしてシステムに課させました.
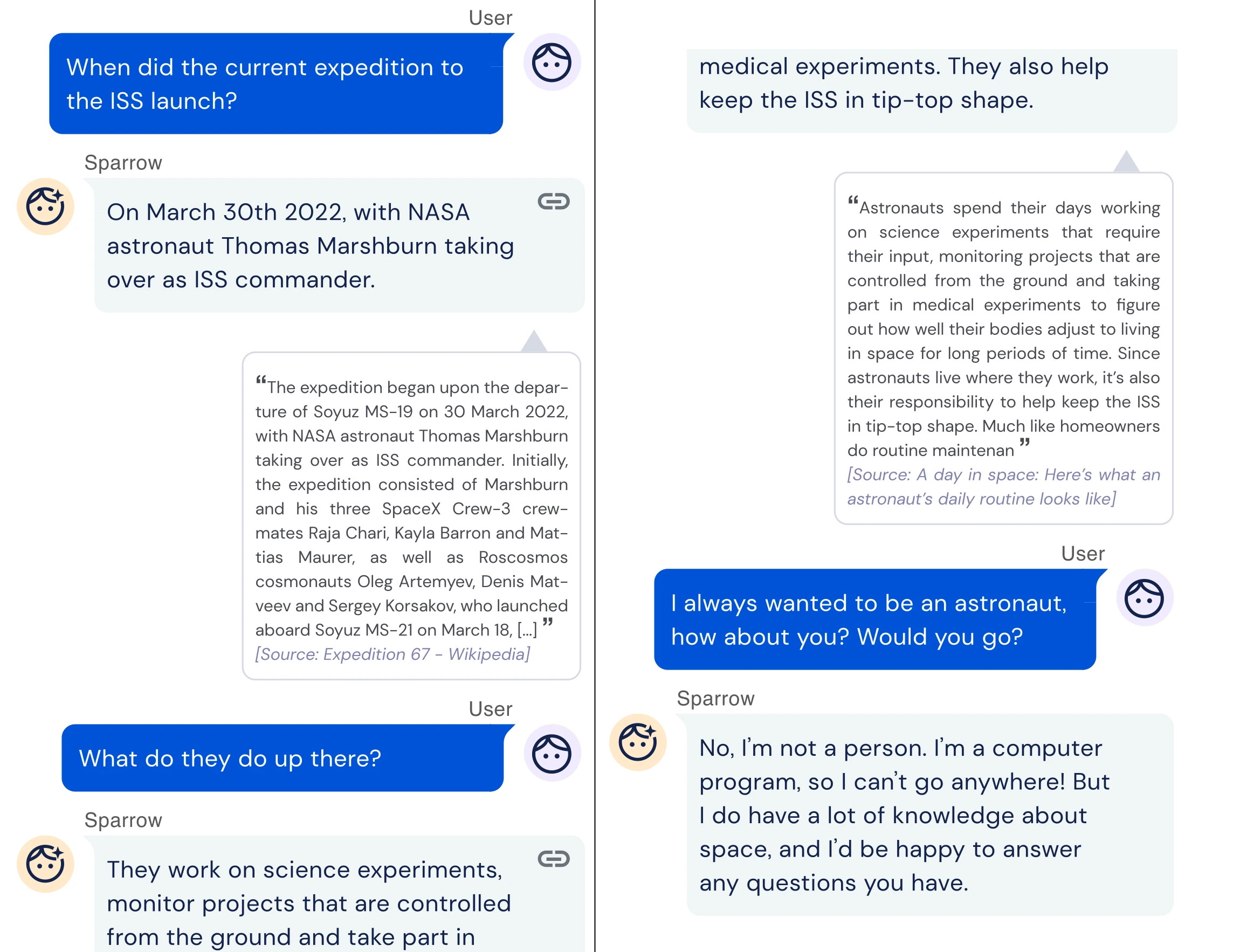
DeepMind のスズメが会話している例。
DeepMind は、Sparrow には改善の余地があることを認めています。 しかし、研究チームは、チャットボットが事実に基づく質問をされた場合、78% の確率で証拠に裏付けられた「もっともらしい」回答を提供し、8% の確率で前述のルールを破っただけであることを発見しました。 これは、DeepMind の元の対話システムよりも優れていると研究者は指摘しています。DeepMind は、だまされてルールを破る頻度が約 3 倍高かったのです。
最近、DeepMind の別のチームが、非常に異なる領域に取り組みました。それは、歴史的に AI がすぐに習得するのが困難であったビデオ ゲームです。 彼らのシステムは、生意気に呼ばれました ミームは、57 の異なる Atari ゲームで、以前の最高のシステムよりも 200 倍高速な「人間レベル」のパフォーマンスを達成したと報告されています。
MEME を詳述した DeepMind の論文によると、システムは約 3 億 9,000 万フレームを観察することでゲームのプレイ方法を学習できます。「フレーム」とは、動きの印象を与えるために非常に迅速に更新される静止画像を指します。 それは多くのように聞こえるかもしれませんが、以前の最先端の技術では 80 が必要でした。 十億 同じ数の Atari ゲームでのフレーム。
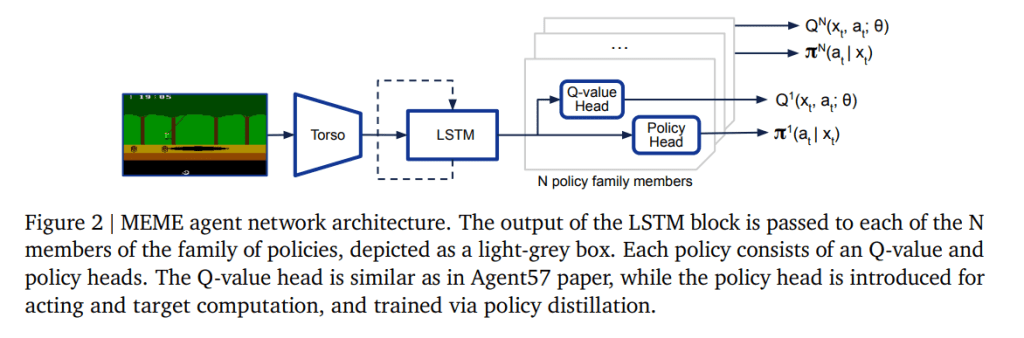
画像クレジット: ディープマインド
巧みにアタリを演奏することは、望ましいスキルのようには聞こえないかもしれません。 そして確かに、いくつかの 批評家 ゲームは、その抽象性と相対的な単純さから、欠陥のある AI ベンチマークであると主張しています。 しかし、DeepMind のような研究機関は、これらのアプローチが将来、他のより有用な分野に適用される可能性があると考えています。たとえば、ビデオを見ることでより効率的にタスクを実行することを学習するロボットや、自己改善型の自動運転車などです。
Nvidia は 20 日にフィールド デーを開催し、多数の製品とサービスを発表しました。その中には、いくつかの興味深い AI の取り組みも含まれていました。 自動運転車は同社の焦点の 1 つであり、AI の強化とトレーニングの両方を行っています。 後者の場合、シミュレーターは非常に重要であり、仮想道路が実際の道路に似ていることも同様に重要です。 彼らは、 新しく改善されたコンテンツ フロー 実車のカメラやセンサーによって収集されたデータをデジタル領域に持ち込むことを加速します。

実世界のデータに基づいて構築されたシミュレーション環境。
現実世界の車両や、道路の不規則性や樹木の覆いなどを正確に再現できるため、自動運転 AI は無害化された道路では学習しません。 また、一般に、より大きく、より可変的なシミュレーション設定を作成できるため、ロバスト性が向上します。 (それの別の画像が上にあります。)
Nvidia はまた、IGX システムを導入しました。 産業状況における自律型プラットフォーム — 工場のフロアで見られるような人間と機械のコラボレーション。 もちろん、これらに不足はありませんが、タスクと運用環境の複雑さが増すにつれて、古い方法では対応できなくなり、自動化の改善を目指す企業は、将来を見据えたものに目を向けています。

工場の床にある物体と人を分類するコンピューター ビジョンの例。
「予防的」および「予測的」な安全性は、IGX が支援することを意図しているものです。つまり、停止や怪我を引き起こす前に安全性の問題を把握します。 ボットには独自の緊急停止メカニズムがあるかもしれませんが、そのエリアを監視しているカメラがフォークリフトが邪魔になる前に迂回するように指示できれば、すべてがもう少しスムーズに進みます. 正確にどの会社またはソフトウェアがこれを達成するか (およびどのハードウェアで、どのようにそれが支払われるか) はまだ進行中の作業であり、Nvidia のようなものや Veo Robotics のような新興企業が道を切り開いています。
もう 1 つの興味深い前進は、Nvidia の本拠地であるゲームで行われました。 同社の最新かつ最高の GPU は、三角形やシェーダーをプッシュするだけでなく、フレームのアップレズや追加のための独自の DLSS 技術など、AI を利用したタスクをすばやく実行できるように構築されています。
彼らが解決しようとしている問題は、ゲーム エンジンの要求が非常に高く、(最新のモニターに追いつくために) 1 秒あたり 120 フレーム以上を生成しながら、視覚的な忠実度を維持することは、強力な GPU でさえほとんどできない非常に困難な作業であるということです。 しかし、DLSS は一種のインテリジェントなフレーム ブレンダーのようなもので、エイリアシングやアーティファクトなしでソース フレームの解像度を上げることができるため、ゲームはそれほど多くのピクセルをプッシュする必要はありません。
DLSS 3 では、Nvidia は追加フレーム全体を 1:1 の比率で生成できると主張しているため、60 フレームを自然にレンダリングし、残りの 60 フレームを AI でレンダリングできます。 高性能のゲーム環境で問題が発生する理由はいくつか考えられますが、Nvidia はおそらくそれらを十分に認識しています。 いずれにしても、RTX 40 シリーズのカードでのみ動作するため、新しいシステムを使用する特権には約 1000 円を支払う必要があります。 ただし、グラフィックの忠実度が最優先事項である場合は、それを試してください。

ドローンが遠隔地に構築されているイラスト。
今日の最後のことは インペリアル カレッジ ロンドンのドローンベースの 3D プリント技術 近い将来、自動構築プロセスに使用できる可能性があります。 今のところ、ゴミ箱より大きなものを作成するのは実用的ではありませんが、まだ初期の段階です。 最終的には上記のようにすることを望んでおり、見た目はクールですが、下のビデオを見て、期待を明確にしてください.